Year Review 2022

What’s the story Rory? Is that the time of the year that you start to reflect about what you did in this year and what you want to do next year. I definitely manage to do a lot of nice… Continue Reading

What’s the story Rory? Is that the time of the year that you start to reflect about what you did in this year and what you want to do next year. I definitely manage to do a lot of nice… Continue Reading

How heya? This was my second time at Web Summit, and I still can say that it is massive. I can say “it is crowded” to the point that it could frustrate all visitors. I spent one hour and twenty… Continue Reading

What’s the crack jack? I had the opportunity to be at Devoxx Belgium 2022, the conference was held from October 10th until October 15th in Antwerp – Belgium. It was amazing. It’s a big event with lots of people, the… Continue Reading
Story Horse? Currently, there is no coroutines implementation in Java, and Project Loom is a proposal implementation. Is not yet clear when this should be added to Java, but there is a big expectation for Java 19. Check out my… Continue Reading
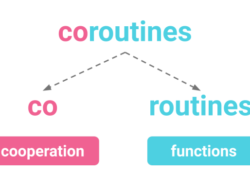
Hey, you! Coroutines is something old that was forgotten for many years, but because of the trending of data-intensive applications nowadays is gaining popularity, and is here to stay, which means that developers will need to learn what coroutines is.… Continue Reading
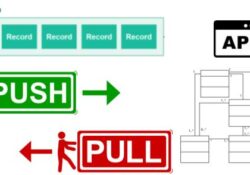
How heya? What are the differences between Data Streams, Java Streams, Reactive Streams, Kafka Streams, Spark Streams, and several others Streams? The term stream does not really say much. A stream is simply a sequence of data elements made available… Continue Reading
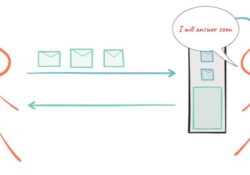
How’s the craic? Reactive Programming is trending nowadays and there is a lot of noise about it at the moment, not all of which is very easy to understand. Reactive Programming or Functional Reactive Programming and Reactive Streams are again… Continue Reading
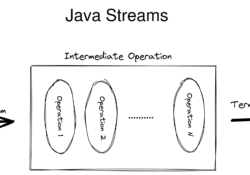
How’s the form? Introduced in Java 8, the Stream API provides a functional approach to processing collections of objects. A stream is a sequence of objects that supports various methods which can be pipelined to produce the desired result. I… Continue Reading

Happy New Year, horses. First post of the year and nothing better than another motivational post. Don’t forget to prepare your year’s resolutions. What book should I read to become a better developer? This is the question that constantly comes… Continue Reading

How’s the lad? This is another blog about Raspberry PI, and today I want to talk about Raspberry Pi Hats or pHats. Thanks to their GPIO headers, most Pi computers can connect to devices called HATs, which stands for Hardware… Continue Reading