
How heya?
What are the differences between Data Streams, Java Streams, Reactive Streams, Kafka Streams, Spark Streams, and several others Streams?
The term stream does not really say much. A stream is simply a sequence of data elements made available over time. So the word stream does not imply any technical details, just that there is data and we can use it over time. It is a generic term that applies to Java Streams, Observables, and even Iterators. This blog might help to clarify your understanding of what the fuss is about.
Let’s check one by one;
Data Streams
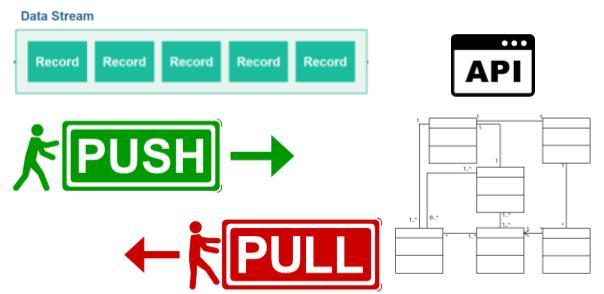
Data streaming is the ongoing transfer of data at a high rate of speed. Most data streams are continuously collecting data from thousands of data sources, and typically send large clusters of smaller-sized data records simultaneously.

Picture 1: Data Streams
Java Stream
From Java 8 streams are wrappers around a data source, allowing us to operate with that data source and making bulk processing convenient and fast. You can think of it as the API that you can use to manipulate data.
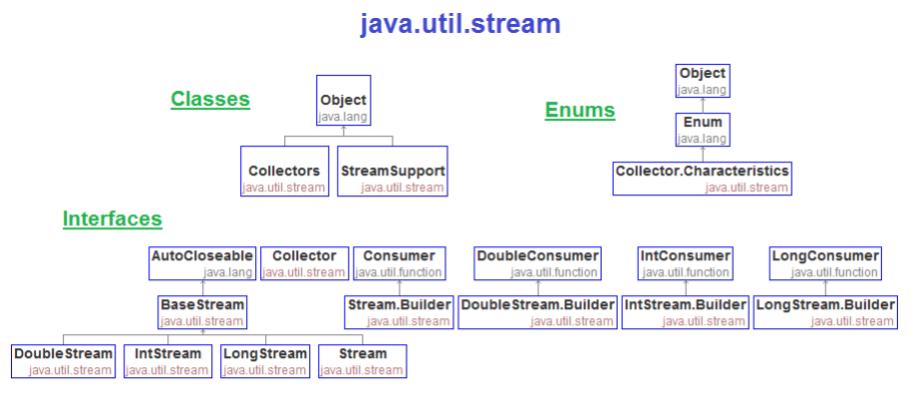
Picture 2: Java Util Stream API
Reactive Streams
Flow API introduced in Java 9
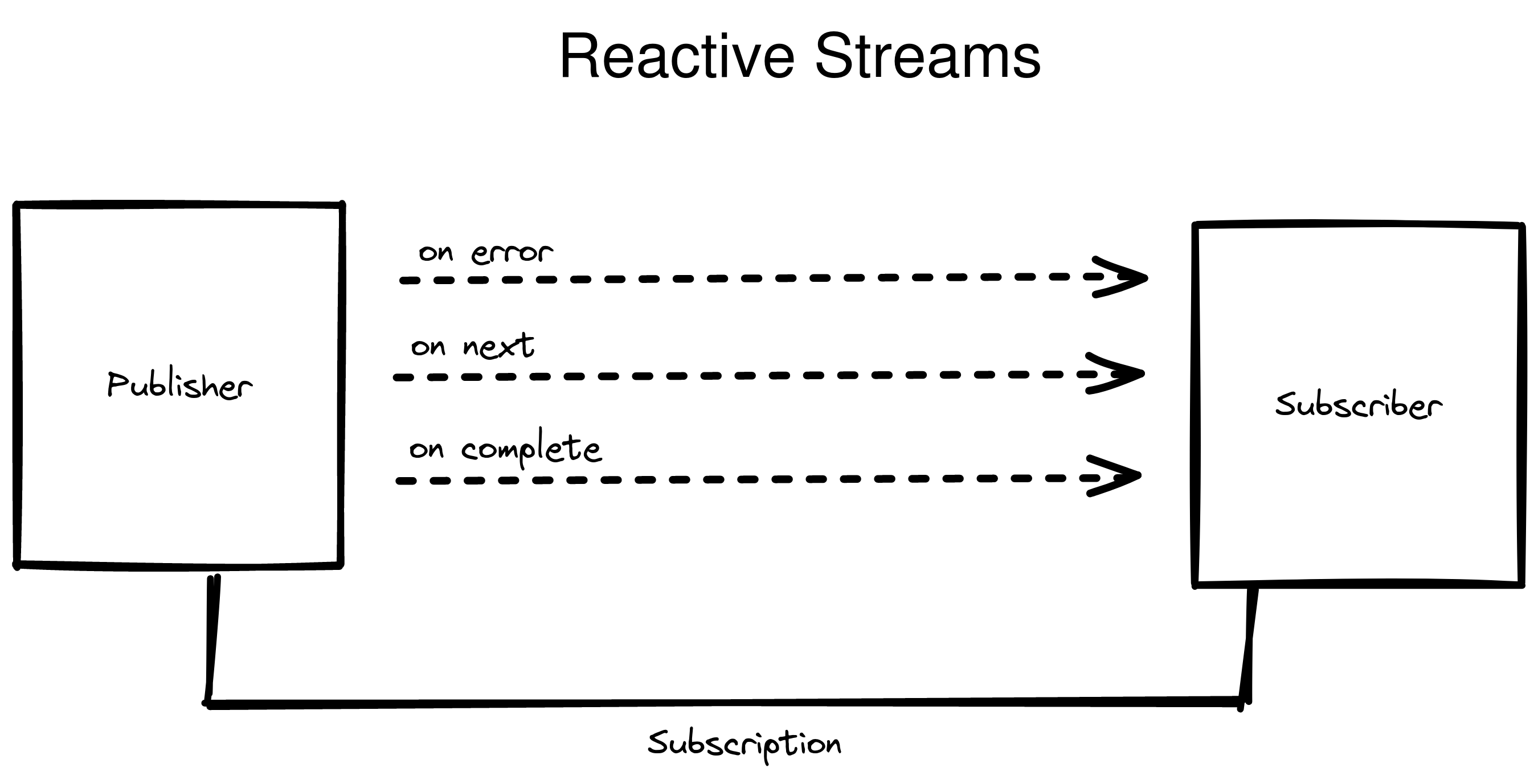
Picture 3: Reactive Streams
While the Streams API introduced in Java 8 is perfect to process data streams, map, reduce and all the variants, the Flow API introduced in Java 9 shines on the communication side request, slow down, drop, block, etc.
The main differences between the most common streams are following:
-
Java Streams
- Reactive Streams: push-based and asynchronous
Reactive programming
Reactive programming, if I try to shrink it to a paragraph, is a way of programming in which the consumers are in control of the Data Flow
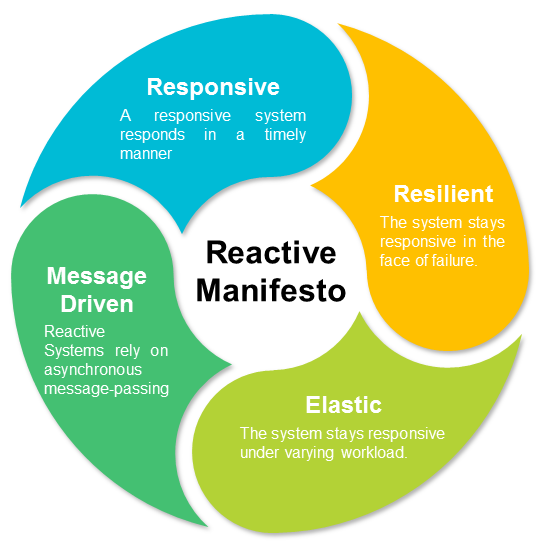
Picture 4: Reactive Manifesto
There are 3 implementations in Java
Reactive Streams
RxJava
Project Reactor
Kafka Streams
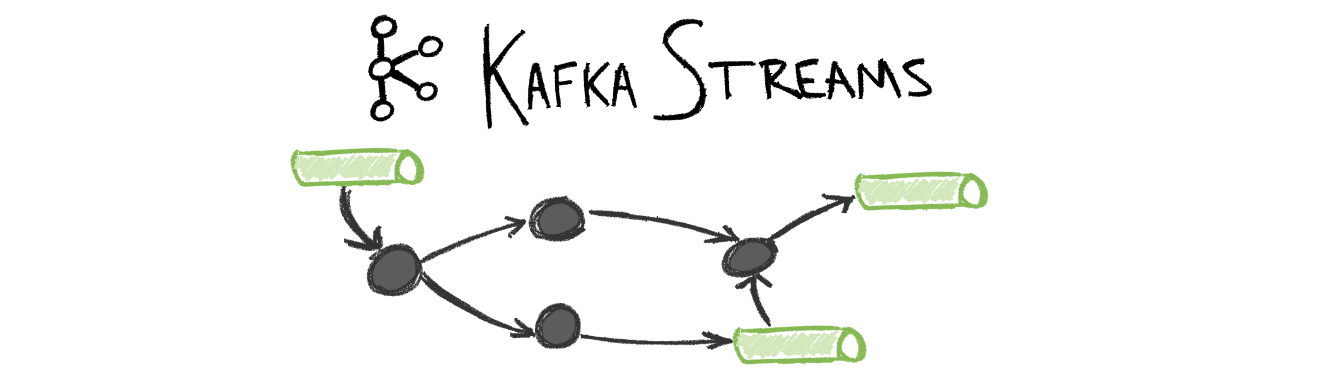
Picture 5: Kafka Streams
Kafka Streams is a client library for building applications and microservices, where the input and output data are stored in an Apache Kafka cluster. It combines the simplicity of writing and deploying standard Java and Scala applications on the client-side with the benefits of Kafka’s server-side cluster technology.
I just realised that I don’t have a blog post about Kafka Streams. Stay tuned for one soon.
Spark Streaming
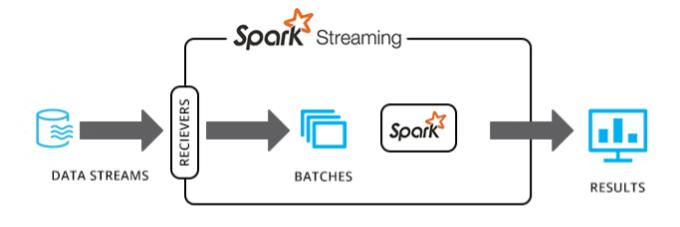
Picture 6: Spark Streaming
Spark Streaming is an extension of the core Spark API that allows data engineers and data scientists to process real-time data from various sources including (but not limited to) Kafka, Flume, and others. This processed data can be pushed out to file systems, databases, and live dashboards.
I just realised that I don’t have a blog post about Spark Streaming. Stay tuned for one soon.

Picture 7: Real example
Conclusion
The term stream does not really say much and it is used in several buzzwords at the moment.
The main difference is about checking if it is pull-based or push-based and synchronous or asynchronous.
Java Streams came from Java 8 and Reactive Streams came from Java 9.
Kafka and Spark Streams are just API name to do something similar to what Java Stream does.
Links
http://www.igfasouza.com/blog/java-stream/
http://www.igfasouza.com/blog/reactive-streams-and-reactive-programming/
http://www.igfasouza.com/blog/learn-kafka-and-event-streams-with-fun/