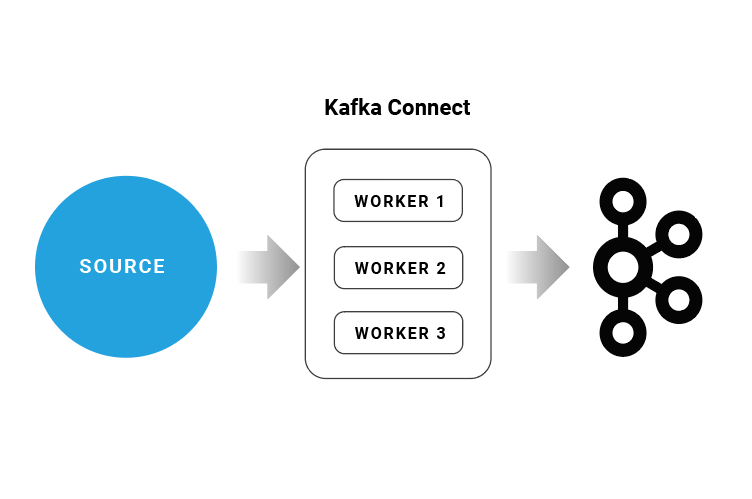
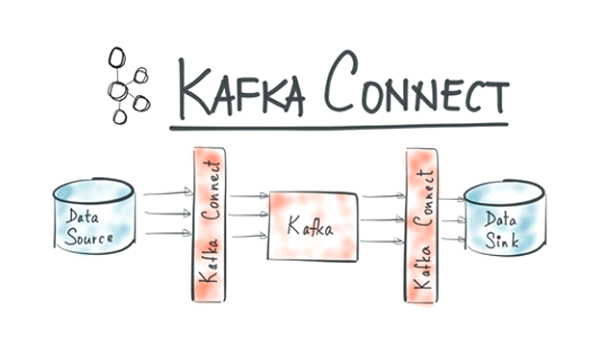
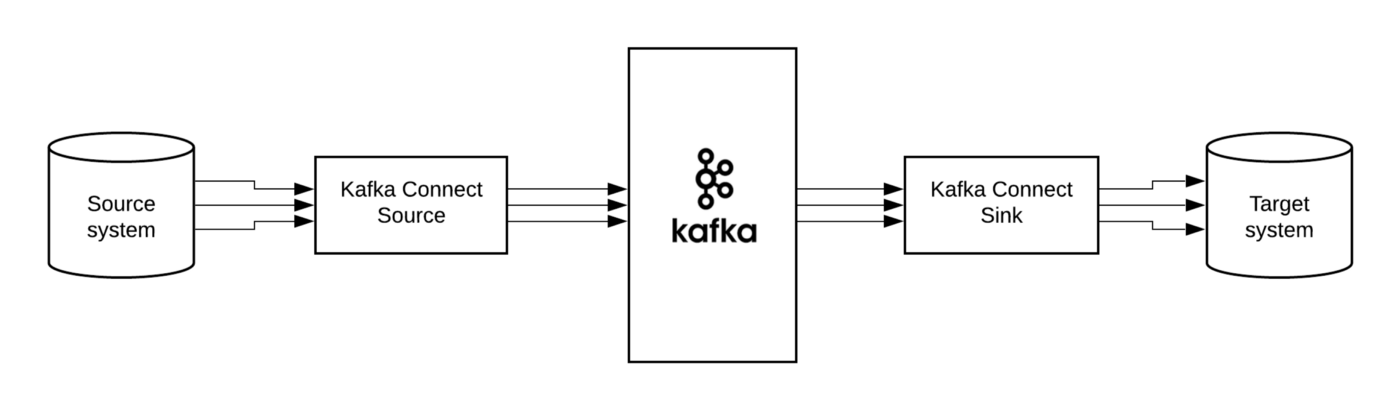
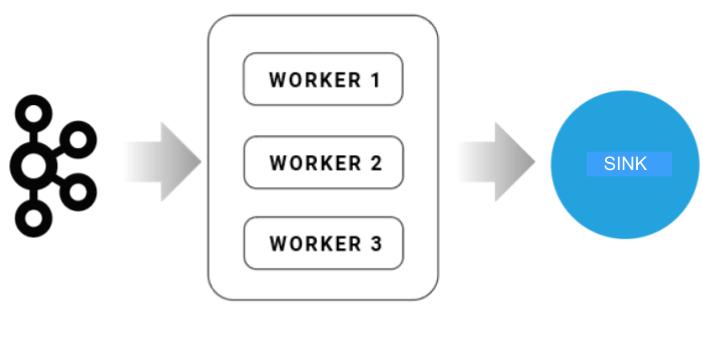
Sink Kafka connect
Well? This blog post is part of my series of posts regarding Kafka Connect. If you’re not familiar with Kafka, I suggest you have a look at some of my previous post; What is Kafka? Kafka Connect Overview Kafka Connector… Continue Reading