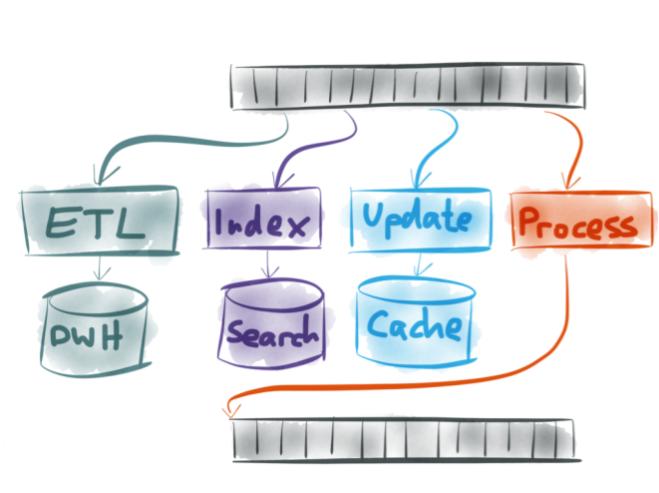
Kafka producer & Consumer Overview
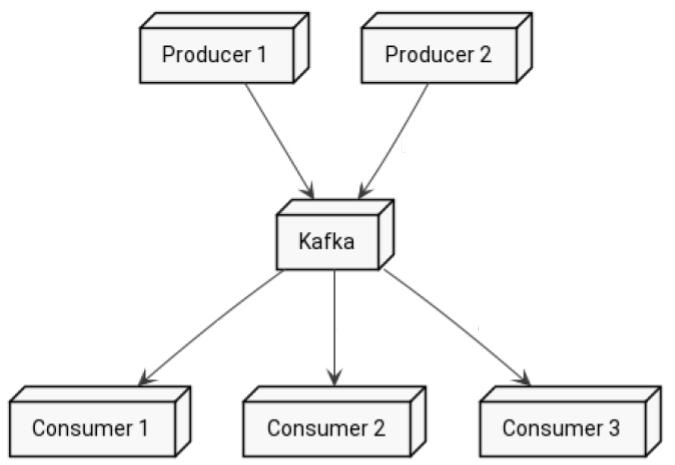
How’s it going horse? If you’re not familiar with Kafka, I suggest you have a look at my previous post “What is Kafka?” before. This blog is just a quick review of Kafka Producer and Consumer. Table of contents 1.… Continue Reading