Web Summit 2022

How heya? This was my second time at Web Summit, and I still can say that it is massive. I can say “it is crowded” to the point that it could frustrate all visitors. I spent one hour and twenty… Continue Reading

How heya? This was my second time at Web Summit, and I still can say that it is massive. I can say “it is crowded” to the point that it could frustrate all visitors. I spent one hour and twenty… Continue Reading

What’s the crack jack? I had the opportunity to be at Devoxx Belgium 2022, the conference was held from October 10th until October 15th in Antwerp – Belgium. It was amazing. It’s a big event with lots of people, the… Continue Reading

Story Horse? All good in the hood? 2021/03/14 Happy PI day with another blog about Raspberry PI, It’s kind of a continuation from my previous blog. Control your house lights in a smart way and check out your energy consumption.… Continue Reading

How the hell are you? 2021/03/12 Smart devices are all of the everyday objects made intelligent with advanced computers, including AI and machine learning, and networked to form the internet of things (IoT). Not just computers and smartphones, but everything:… Continue Reading
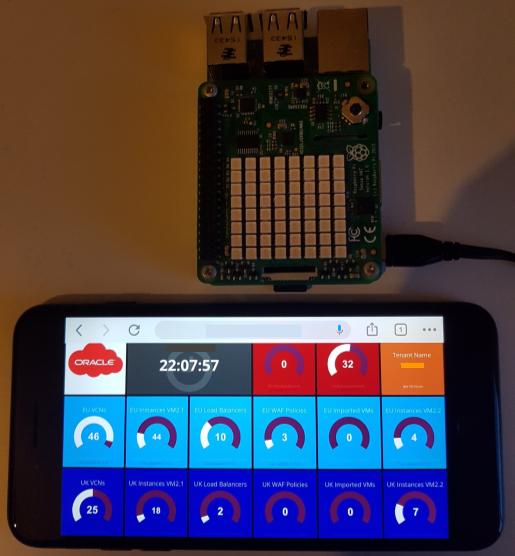
What’s up? 2021/03/05 This is another blog about Raspberry PI, and today I want to show how I did a simple Kafka cluster demo. It’s kind of a continuation from my two previous blogs, Kafka at the edge with Raspberry… Continue Reading

How’s the craic? 2021/03/03 This is another blog about Raspberry PI, and today I want to show how I did a simple Kafka cluster demo using the Inky pHAT. It’s kind of a continuation from my previous blog, Kafka at… Continue Reading

How’s the man? 2021/03/01 This is another blog about Raspberry PI, and today I want to show how I did a simple Kafka cluster demo using Sense Hat & GFX Hat. If you’re not familiar with Kafka, I suggest you… Continue Reading

How’s it going there? 2021/02/26 The Rainbow HAT is an add-on board for Raspberry Pi, is a collection of sensors, inputs and outputs from popular components in one board, which we can attach the 40 pin pin-out of the Pi.… Continue Reading

How goes the battle? 2021/02/22 This post is to show how I created a Helidon demo with a Raspberry PI. A simple web application to control a 14 segments display. This is another blog about Java on Raspberry PI. Originally… Continue Reading

What’s the crack jack? Yesterday I went to Predict Conference, and I need to say thanks to Oracle for providing this experience for me. Takeaways My first time at Predict Conference, my first impression: it is a nice conference to… Continue Reading