

Alright Boyo?
Donald Trump has been forced to correct his tweet boasting about his writing ability after it was filled with spelling mistakes.
Here
The US president posted on the social media website to defend his writing style and criticise the “Fake News” media for searching for mistakes in his tweets.
The tweet itself had a few errors: Instead of “pore over” Mr Trump wrote “pour over” and instead of “bestselling” he wrote “best selling”.
There are also question marks over how many books the former businessman has actually written.

The tweet received a number of mocking responses before it was deleted and reposted with the “pour over” error corrected.
With this and because I already have several projects using his tweets, I came up with the idea to analyze all Donald trump Tweets and check all spelling mistakes.
I work in a data analytics company and I decide to ask for suggestions about the idea.
Talking with colleagues here I decided to add a blog post.
Here I add a big thanks to my colleagues who helped me to do this analysis.
Brian Sullivan and Aishwarya Mundalik
I was collecting all Tweets from him even on fly. You can check in my GitHub a Python script to get all Tweets from a user account.
Just a small change in the code to save a csv file with tweet_id and word columns:
1 2 3 4 5 6 7 8 9 | with open('%s_tweets.csv' % screen_name, 'wb') as f: writer = csv.writer(f, delimiter='|') writer.writerow(["id","words"]) for items in outtweets: index = items[0] out=items[1] word_array=out.split() for word in word_array: writer.writerow((index , word)) |
And the R code
The code is using the Hunspell R API to analyze the words.
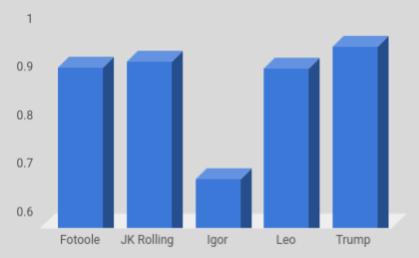
First I checked Donald Trump’s tweets, and then I decided to compare against some others;
I chose Leo Varadkar and Fintan O’Toole because I’m in Ireland and I choose J.K. Rowling because she is a writer and according to the news she was one of the people to make a lot of jokes about the case.
1 2 3 4 5 6 7 8 9 10 | Output -----> > mean(TT_Final$correct/TT_Final$n) (Trunmp Tweets) [1] 0.9645933 > mean(LT_Final$correct/LT_Final$n) (Leo Tweets) [1] 0.9187365 > mean(RT_Final$correct/RT_Final$n) (J_K Rolling tweets) [1] 0.9338411 > mean(FT_Final$correct/FT_Final$n) (Fotoole Tweets) [1] 0.9212394 |
The result was impressive, Donald Trump has the best value. This means that he has fewer mistakes than the others. The API just states whether the spelling is correct or not for each word.
Unfortunately, the API just checks words and not grammar or syntax- and for some values like single characters, the result is ‘true’ when it may not make sense.
Here we can see a sample result.
1 2 3 4 5 6 7 8 | ID WORD RESULT 1017190186269184000 but TRUE 1017190186269184000 it TRUE 1017190186269184000 isn FALSE 1017190186269184000 t TRUE 1017190186269184000 nearly TRUE 1017190186269184000 U TRUE 1017190186269184000 S TRUE |
This is just a basic analysis and the result are completely dependent on the API.
It would be really nice to do a grammar or syntax analysis as well.
The website politwoops.eu follows some politicians on Twitter and they show a list of deleted tweets from each one. I manage to get the last 60 tweets from Donald Trump and the result is:
1 2 | > mean(DD_Final$correct/DD_Final$n) (Deleted Donald Trump tweets) [1] 0.958324 |
This proves that he actually deleted the tweet and posted it again and that he makes some mistakes.
I just analysed the last 3000 tweets for each account.
For fun, I have a look at my tweets as well:
1 2 | > mean(Igor_Final$correct/IG_Final$n) [1] 0.6915032 |
And here is my defence … hehehe, Apparent IT words are not correct.
1 2 3 4 5 6 7 8 9 10 11 | ID WORD RESULT 956884676173553664 GDG FALSE 956884676173553664 Hackathon FALSE 950817131503013888 Hacktoberfest FALSE 947550776913735680 Flume FALSE 947550776913735680 Spark FALSE 943640519502106624 sudo FALSE 943640519502106624 init FALSE 943640519502106624 Brazil2018 FALSE 936178221153910784 O'Reilly's FALSE 936178221153910784 Hadoop FALSE |
I put everything in my Github, so you can get the code and play with. Just change the Twitter account and check yourself.