
Hey you!
if you’re not familiar with Big Data or Data lake, I suggest you have a look at my previous post “What is Big Data?” and “What is data lake?” before.
This post is a collection of links, videos, tutorials, blogs and books that I found mixed with my opinion.
Table of contents
01. What is Stream processing?
02. Martin Kleppmann
03. Typical use cases
04. Pattern
05. Evaluation: Choose a Stream Processing Framework or a Product or Both?
06. Vertical vs. Horizontal Scaling
07. Streaming is better with SQL
08. Streaming Windows
09. Why Stream Processing
10. Final considerations
11. Book
12. Influence’s List
13. Links
Stream processing is becoming something like a “grand unifying paradigm” for data processing. Outgrowing its original space of real-time data processing, stream processing is becoming a technology that offers new approaches to data processing (including batch processing), real-time applications, and even distributed transactions.
1. What is Stream Processing?
Stream processing is the act of continuous incorporate new data to compute a result. In stream processing, the input data is unbounded and has no predetermined beginning or end. It simply forms a series of events that arrives at the stream processing system e.g. credit card transactions, clicks on a website, or sensor readings from internet of things devices.
Streaming is a data distribution technique where data producers write data records into an ordered data stream from which data consumers can read that data in the same order. Here is a simple data streaming diagram illustrating a data producer, a data stream and a data consumer

Each data streaming product makes a certain set of assumptions about the use cases and processing techniques to support. These assumptions leads to certain design choices, which affect what types of stream processing behaviour you can implement with them.
From wikipedia;
Stream processing is a computer programming paradigm, equivalent to dataflow programming, event stream processing, and reactive programming, that allows some applications to more easily exploit a limited form of parallel processing.
Stream Processing is a powerful technology that can scan huge volumes of data coming from sensors, credit card swipes, clickstreams and other inputs, and find actionable insights nearly instantaneously. For example, Stream Processing can detect a single fraudulent transaction in a stream containing millions of legitimate purchases, act as a recommendation engine to determine what ad or promotion to display for a particular customer while he or she is actually shopping or compute the optimal price for a car service ride in only a few seconds.
The term “Stream Processing” means that the data is coming into the processing engine as a continuous “stream” of events produced by some outside system or systems, and the processing engine works so fast that all decisions are made without stopping the data stream and storing the information first.
Streaming data and event-driven architectures are rising in popularity. The ideas have been around for a while, but technological and architectural advances have made into reality capabilities like stream processing and even function-based (aka “serverless”) computing. In many cases, the ability to act on data quickly is more valuable than a new method for batch-processing or historical data analysis.
I Googled about and I found;
Streaming is processing of data in motion.
Streaming is data that is continuously generated by different sources.
Streaming is the continuous high-speed transfer of large amounts of data from a source system to a target.
Programming paradigm that allows some applications to more easily exploit a limited form of parallel processing.
Streaming decouple data producers and data consumers from each other. When a data producer simply writes its data to a data stream, the producer does not need to know the consumers that read the data. Consumers can be added and removed independently of the producer. Consumers can also start and stop or pause and resume their consumption without the data producer needing to know about it. This decoupling simplifies the implementation of both data producers and consumers.
A data stream can be persistent, in which case it is sometimes referred to as a log or a journal. A persistent data stream has the advantage that the data in the stream can survive a shutdown of the data streaming service, so no data records are lost.
Persistent data streaming services can typically hold larger amounts of historic data than a data streaming service that only holds records in memory. Some data streaming services can even hold historic data all the way back to the first record written to the data stream. Others only hold e.g. a number of days of historic data.
In the cases where a persistent data stream holds the full history of records, consumers can replay all these records and recreate their internal state based on these records. In case a consumer discovers a bug in its own code, it can correct that code and replay the data stream to recreate its internal database.
2. Martin Kleppmann
Martin Kleppmann is the author of the book “Designing Data Intensive Applications”, and he has some nice papers/presentations;

https://www.confluent.io/blog/turning-the-database-inside-out-with-apache-samza/
https://martin.kleppmann.com/2015/01/29/stream-processing-event-sourcing-reactive-cep.html
https://www.oreilly.com/learning/making-sense-of-stream-processing
Two ideas came from this;
- All the BuzzWords are the same thing;
- The concept of Streaming came from Database “Replication”;
1. BuzzWords
Some people call it stream processing. Others call it Event Sourcing or CQRS. Some even call it Complex Event Processing. Sometimes, such self-important buzzwords are just smoke and mirrors, invented by companies who want to sell you stuff. But sometimes, they contain a kernel of wisdom which can really help us design better systems.
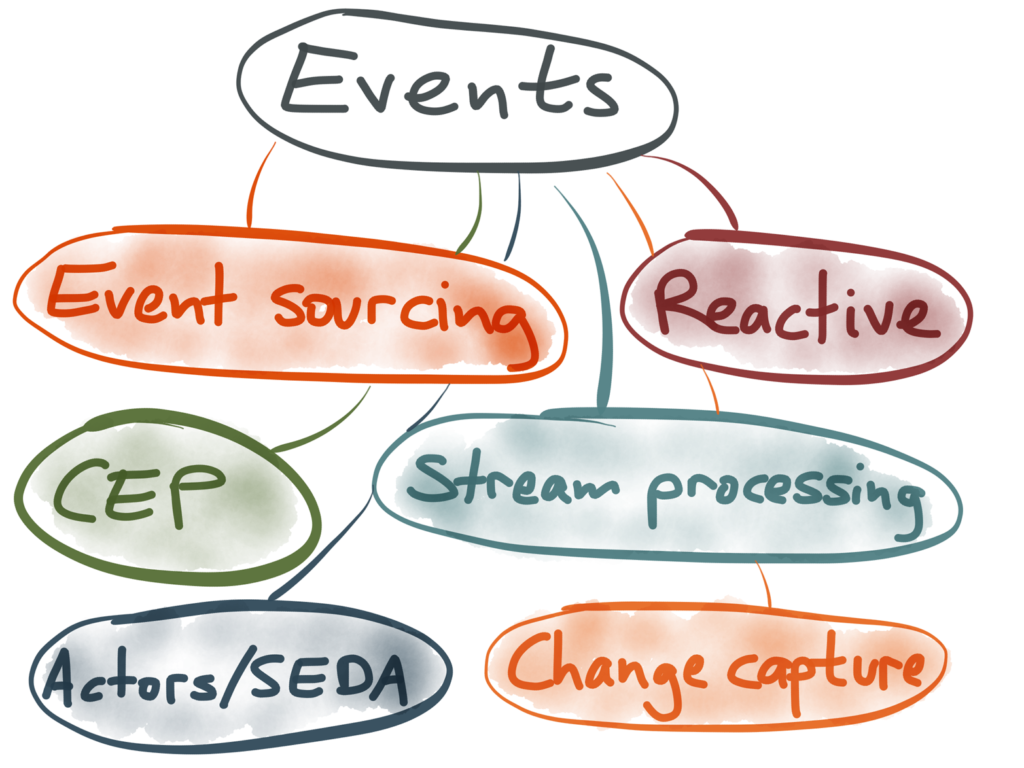
The idea of structuring data as a stream of events is nothing new, and it is used in many different fields. Even though the underlying principles are often similar, the terminology is frequently inconsistent across different fields, which can be quite confusing. Although the jargon can be intimidating when you first encounter it, don’t let that put you off; many of the ideas are quite simple when you get down to the core.
But there’s some Differences.
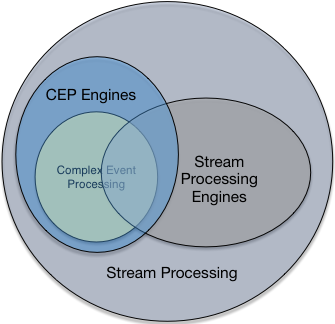
In this article you can see some differences and similarities.
https://iwringer.wordpress.com/2015/12/15/cep-vs-streaming-processing-vs-cep-engines-vs-streaming-analytic-engines/
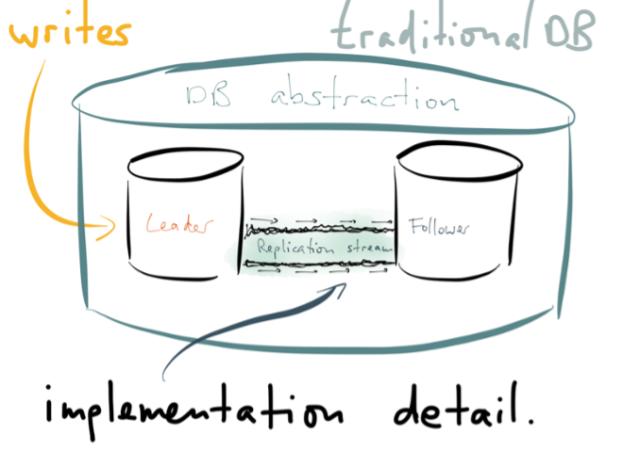
2. Replication
if we took that replication stream, and made it a first-class citizen in our data architecture? What if we changed our infrastructure so that the replication stream was not an implementation detail, but a key part of the public interface of the database? What if we turn the database inside out, take the implementation detail that was previously hidden, and make it a top-level concern? What would that look like?
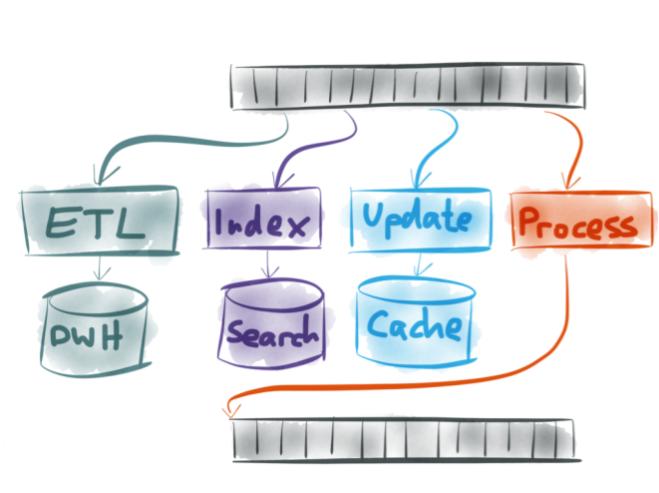
3. Typical use cases
Stream Processing is rapidly gaining popularity and finding applications in various business domains. Found its first uses in the finance industry, as stock exchanges moved from floor-based trading to electronic trading. Today, it makes sense in almost every industry – anywhere where you generate stream data through human activities, machine data or sensors data. Assuming it takes off, the Internet of Things will increase volume, variety and velocity of data, leading to a dramatic increase in the applications for stream processing technologies.
Some use cases where stream processing can solve business problems include:
- Network monitoring
- Intelligence and surveillance
- Risk management
- E-commerce
- Fraud detection
- Smart order routing
- Transaction cost analysis
- Pricing and analytics
- Market data management
- Algorithmic trading
- Data warehouse augmentation
Here is a short list of well-known, proven applications of Stream Processing:
- Clickstream analytics can act as a recommendation engine providing actionable insights used to personalize offers, coupons and discounts, customize search results, and guide targeted advertisements — all of which help retailers enhance the online shopping experience, increase sales, and improve conversion rates.
- Preventive maintenance allows equipment manufacturers and service providers to monitor quality of service, detect problems early, notify support teams, and prevent outages.
- Fraud detection alerts banks and service providers of suspected frauds in time to stop bogus transactions and quickly notify affected accounts.
- Emotions analytics can detect an unhappy customer and help customer service augment the response to prevent escalations before the customer’s unhappiness boils over into anger.
- A dynamic pricing engine determines the price of a product on the fly based on factors such as current customer demand, product availability, and competitive prices in the area.
Common Usage Pattern for In-Stream Analytics
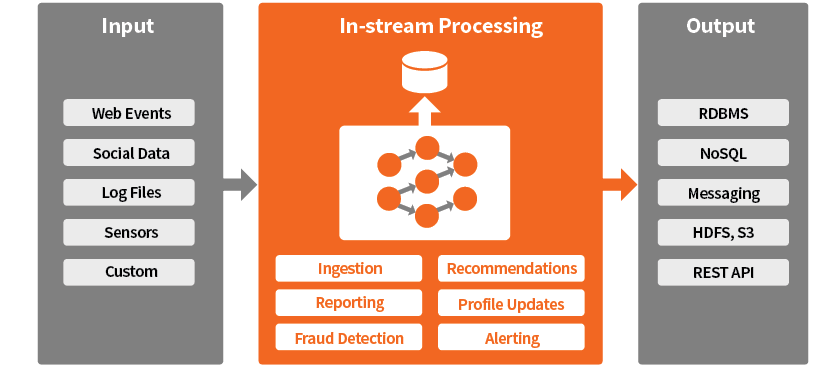
4. Pattern
Writing Streaming Applications requires very different thinking patterns from writing code with a language like Java. A better understanding of common patterns in Stream Processing will let us understand the domain better and build tools that handle those scenarios.
Pattern 1: Preprocessing
Preprocessing is often done as a projection from one data stream to the other or through filtering. Potential operations include
- Filtering and removing some events
- Reshaping a stream by removing, renaming, or adding new attributes to a stream
- Splitting and combining attributes in a stream
- Transforming attributes
For example, from a twitter data stream, we might choose to extract the fields: author, timestamp, location, and then filter them based on the location of the author.
Pattern 2: Alerts and Thresholds
This pattern detects a condition and generates alerts based on a condition. (e.g. Alarm on high temperature). These alerts can be based on a simple value or more complex conditions such as rate of increase etc.
For an example, in TFL (Transport for London) Demo video based on transit data from London, we trigger a speed alert when the bus has exceeded a given speed limit.
We can generate alerts for scenarios such as the server room temperature is continually increasing for the last 5 mins.
Pattern 3: Simple Counting and Counting with Windows
This pattern includes aggregate functions like Min, Max, Percentiles etc, and they can be counted without storing any data. (e.g. counting the number of failed transactions).
However, counts are often used with a time window attached to it. ( e.g. failure count last hour). There are many types of windows: sliding windows vs. batch (tumbling) windows and time vs. length windows. There are four main variations.
- Time, Sliding window: keeps each event for the given time window, produce an output whenever a new event has added or removed.
- Time, Batch window: also called tumbling windows, they only produce output at the end of the time window
- Length, Sliding: same as the time, sliding window, but keeps a window of n events instead of selecting them by time.
- Length, Batch window: same as the time, batch window, but keeps a window of n events instead of selecting them by time
There are special windows like decaying windows and unique windows.
Pattern 4: Joining Event Streams
The main idea behind this pattern is to match up multiple data streams and create a new event steam. For an example, let’s assume we play a football game with both the players and the ball having sensors that emit events with current location and acceleration. We can use “joins” to detect when a player has kicked the ball. To that end, we can join the ball location stream and the player stream on the condition that they are close to each other by one meter and the ball’s acceleration has increased by more than 55m/s^2.
Among other use cases are combining data from two sensors, and detecting the proximity of two vehicles. Please refer to Stream Processing 101: From SQL to Streaming SQL in 10 Minutes for more details.
Pattern 5: Data Correlation, Missing Events, and Erroneous Data
This pattern and the pattern four a has lot in common where here too we match up multiple streams. In addition, we also correlate the data within the same stream. This is because different data sensors can send events at different rates, and many use cases require this fundamental operator.
Following are some possible scenarios.
- Matching up two data streams that send events at different speeds
- Detecting a missing event in a data stream ( e.g. detect a customer request that has not been responded within 1 hour of its reception. )
- Detecting erroneous data (e.g. Detect failed sensors using a set of sensors that monitor overlapping regions and using those redundant data to find erroneous sensors and removing their data from further processing)
Pattern 6: Interacting with Databases
Often we need to combine the real time data against the historical data stored in a disk. Following are a few examples.
- When a transaction happened, look up the age using the customer ID from customer database to be used for Fraud detection (enrichment)
- Checking a transaction against blacklists and whitelists in the database
- Receive an input from the user (e.g. Daily discount amount may be updated in the database, and then the query will pick it automatically without human intervention.)
Pattern 7: Detecting Temporal Event Sequence Patterns
Using regular expressions with strings, we detect a pattern of characters from a sequence of characters. Similarly, given a sequence of events, we can write a regular expression to detect a temporal sequence of events arranged on time where each event or condition about the event is parallel to a character in a string in the above example.
A frequently cited example, although bit simplistic, is that a thief, having stolen a credit card, would try a smaller transaction to make sure it works and then do a large transaction. Here the small transaction followed by a large transaction is a temporal sequence of events arranged on time and can be detected using a regular expression written on top of an event sequence.
Such temporal sequence patterns are very powerful. For example, the following video shows a real time analytics done using the data collected from a real football game. This was the dataset taken from DEBS 2013 Grand Challenge.
In the video, we used patterns on event sequence to detect the ball possession, the time period a specific player controlled the ball. A player possessed the ball from the time he hits the ball until someone else hits the ball. This condition can be written as a regular expression: a hit by me, followed by any number of hits by me, followed by a hit by someone else. (We already discussed how to detect the hits on the ball in Pattern 4: Joins).
Pattern 8: Tracking
The eighth pattern tracks something over space and time and detects given conditions.
Following are few examples
- Tracking a fleet of vehicles, making sure that they adhere to speed limits, routes, and geo-fences.
- Tracking wildlife, making sure they are alive (they will not move if they are dead) and making sure they will not go out of the reservation.
- Tracking airline luggage and making sure they are not been sent to wrong destinations
- Tracking a logistic network and figure out bottlenecks and unexpected conditions.
For example, TFL Demo we discussed under pattern 2 shows an application that tracks and monitors London buses using the open data feeds exposed by TFL(Transport for London).
Pattern 9: Detecting Trends
We often encounter time series data. Detecting patterns from time series data and bringing them into operator attention are common use cases.
Following are some of the examples of tends.
- Rise, Fall
- Turn (switch from a rise to a fall)
- Outliers
- Complex trends like triple bottom etc.
These trends are useful in a wide variety of use cases such as
- Stock markets and Algorithmic trading
- Enforcing SLA (Service Level Agreement), Auto Scaling, and Load Balancing
- Predictive maintenance ( e.g. guessing the Hard Disk will fill within next week)
Pattern 10: Running the same Query in Batch and Realtime Pipelines
This pattern runs the same query in both Relatime and batch pipeline. It is often used to fill the gap left in the data due to batch processing. For example, if batch processing takes 15 minutes, results would lack the data for the last 15 minutes.
The idea of this pattern, which is sometimes called “Lambda Architecture” is to use real time analytics to fill the gap. Jay Kreps’s article “Questioning the Lambda Architecture” discusses this pattern in detail.
Pattern 11: Detecting and switching to Detailed Analysis
The main idea of the pattern is to detect a condition that suggests some anomaly, and further analyze it using historical data. This pattern is used with the use cases where we cannot analyze all the data with full detail. Instead, we analyze anomalous cases in full detail. Following are a few examples.
-
Use basic rules to detect Fraud (e.g. large transaction), then pull out all transactions done against that credit card for a larger time period (e.g. 3 months data) from a batch pipeline and run a detailed analysis
- While monitoring weather, detect conditions like high temperature or low pressure in a given region and then start a high resolution localized forecast on that region.
- Detect good customers, for example through the expenditure of more than $1000 within a month, and then run a detailed model to decide the potential of offering a deal.
Pattern 12: Using a Model
The idea is to train a model (often a Machine Learning model), and then use it with the Realtime pipeline to make decisions. For example, you can build a model using R, export it as PMML (Predictive Model Markup Language) and use it within your realtime pipeline.
Among examples is Fraud Detections, Segmentation, Predict next value, Predict Churn. Also see InfoQ article, Machine Learning Techniques for Predictive Maintenance, for a detailed example of this pattern.
Pattern 13: Online Control
There are many use cases where we need to control something online. The classical use cases are the autopilot, self-driving, and robotics. These would involve problems like current situation awareness, predicting the next value(s), and deciding on corrective actions.
You can implement most of these use cases with a Stream Processor that supports a Streaming SQL language.
This pattern list came from (9th ACM International Conference on Distributed Event-Based Systems), describing a set of real time analytics patterns.
You can find details about pattern implementations and source code from here.
Monal Daxini presents a blueprint for streaming data architectures and a review of desirable features of a streaming engine. He also talks about streaming application patterns and anti-patterns, and use cases and concrete examples using Apache Flink.
Patterns of Streaming Applications
5. Evaluation: Choose a Stream Processing Framework or a Product or Both?
There are many different data streaming products, and it can be hard to know where to start studying them, and which products do what etc.
The typical evaluation process (long list, short list, proof of concept) is obligatory before making a decision.
- A stream processing programming language for streaming analytics
- Visual development and debugging instead of coding
- Real-time analytics
- Monitoring and alerts
- Support for fault tolerance, and highly optimized performance
- Product maturity
- In the case of TIBCO, a live data mart and operational command and control center for business users
- Out-of-the-box connectivity to plenty of streaming data sources
- Commercial support
- Professional services and training.
Think about which of the above features you need for your project. In addition, you have to evaluate the costs of using a framework against productivity, reduced effort and time-to-market using a product before making your choice.
Besides evaluating the core features of stream processing products, you also have to check integration with other products. Can a product work together with messaging, Enterprise Service Bus (ESB), Master Data Management (MDM), in-memory stores, etc. in a loosely coupled, but highly integrated way? If not, there will be a lot of integration time and high costs.
6. Vertical vs. Horizontal Scaling
Vertical scaling means running your data streaming storage and processors on a more powerful computer. Vertical scaling is also sometimes referred to as scaling up. You scale up the size and speed of its disk, memory, speed of CPUs, possibly CPU cores too, graphics cards etc.
Horizontal scaling means distributing the workload among multiple computers. Thus, the data in the data stream is distributed among multiple computers, and the applications processing the data streams are too (or at least they can be). Horizontal scaling is also sometimes referred to as scaling out. You scale out from a single computer to multiple computers.
Distributing the messages of a data stream onto multiple computers is also referred to as partitioning the data stream.
1. Round Robin Partitioning
Round robin data stream partitioning is the simplest way to partition the messages of a data stream across multiple computers. The round robin partitioning method simply distributes the messages evenly and sequentially among the computers. In other words, the first message is stored on the first computer, the second message on the second computer etc. When all computers have received a message from the stream, the round robin method starts from the first computer again.
2. Key Based Partitioning
Key based partitioning distributes the message across different computers based on a certain key value read from each message. Commonly the identifying id (e.g. primary key) is used as key to distribute the messages. Typically, a hash value is calculated from each key value, and that hash value is then used to map the message to one of the computers in the cluster.
Stream Processing and DWH
A DWH is a great tool to store and analyze structured data. You can store terabytes of data and get answers to your queries about historical data within seconds. DWH products such as Teradata or HP Vertica were built for this use case. However the ETL processes often take too long. Business wants to query up-to-date information instead of using an approach where you may only get information about what happened yesterday. This is where stream processing comes in and feeds all new data into the DWH immediately.
Stream Processing and Hadoop
A big data architecture contains stream processing for real-time analytics and Hadoop for storing all kinds of data and long-running computations.
Hadoop initially started with MapReduce, which offers batch processing where queries take hours, minutes or at best seconds. This is and will be great for complex transformations and computations of big data volumes. However, it is not so good for ad hoc data exploration and real-time analytics. Multiple vendors have though made improvements and added capabilities to Hadoop that make it capable of being more than just a batch framework.
DWH, Hadoop and stream processing complement each other very well. Therefore, the integration layer is even more important in the big data era, because you have to combine more and more different sinks and sources.
Since 2016, a new idea called Streaming SQL has emerged. We call a language that enables users to write SQL like queries to query streaming data as a “Streaming SQL” language. Almost all Stream Processors now support Streaming SQL.
7. Streaming is better with SQL
Let’s assume that you picked a stream processor, implemented some use cases, and it’s working. Now you sit down to savor the win. However, given that you can simply write SQL or something like SQL when doing batch processing, why should you have to write all this code? Shouldn’t you be able to do streaming with SQL? The answer is yes, you should. Such streaming SQL exists. Again there are many offerings. Unfortunately, unlike SQL, there is no standard streaming SQL syntax. There are many favors, which follow SQL but have variations.
SQL is a powerful language for querying structured data. It is designed as a set of independent operators: projection, filter, joins, and grouping, which can be recombined to create very powerful queries.
Following are some advantages of streaming SQL languages:
- It’s easy to follow and learn for the many people who know SQL.
- It’s expressive, short, sweet and fast!!
- It defines core operations that cover 90% of problems.
- Streaming SQL language experts can dig in when they like by writing extensions!
- A query engine can better optimize the executions with a streaming SQL model. Most optimizations are already studied under SQL, and there is much we can simply borrow from database optimizations.
Let us walk through a few of the key operators. Just as SQL can cover most data queries on data stored in a disk, streaming SQL can cover most of the queries on streaming data. Without streaming SQL, programmers would have to hand code each operator, which is very complicated and hard work.
Concepts in SQL, such as “group by” and “having” clauses, usually work similarly with streaming SQL languages.
Streaming SQL has two additional concepts not covered by SQL: windows and joins, which handle the complexities of streaming. Let’s understand each of them.
8. Streaming Windows
Although batch can be handled as a special case of stream processing, analyzing never-ending streaming data often requires a shift in the mindset and comes with its own terminology (for example, “windowing” and “at-least-once”/”exactly-once” processing). This shift and the new terminology can be quite confusing for people being new to the space of stream processing.
Consider the example of a traffic sensor that counts every 15 seconds the number of vehicles passing a certain location. The resulting stream could look like:
![]()
If you would like to know, how many vehicles passed that location, you would simply sum the individual counts. However, the nature of a sensor stream is that it continuously produces data. Such a stream never ends and it is not possible to compute a final sum that can be returned. Instead, it is possible to compute rolling sums, i.e., return for each input event an updated sum record. This would yield a new stream of partial sums.
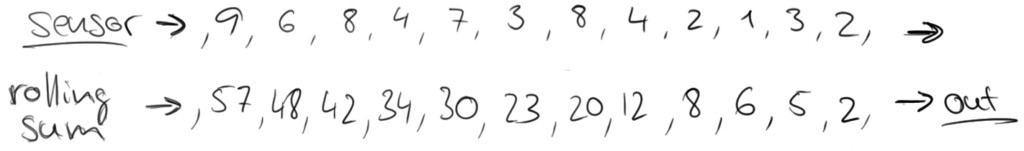
However, a stream of partial sums might not be what we are looking for, because it constantly updates the count and even more important, some information such as variation over time is lost. Hence, we might want to rephrase our question and ask for the number of cars that pass the location every minute. This requires us to group the elements of the stream into finite sets, each set corresponding to sixty seconds. This operation is called a tumbling windows operation.
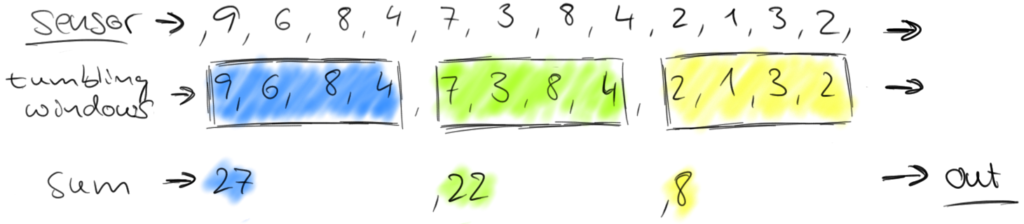
Tumbling windows discretize a stream into non-overlapping windows. For certain applications it is important that windows are not disjunct because an application might require smoothed aggregates. For example, we can compute every thirty seconds the number of cars passed in the last minute. Such windows are called sliding windows.
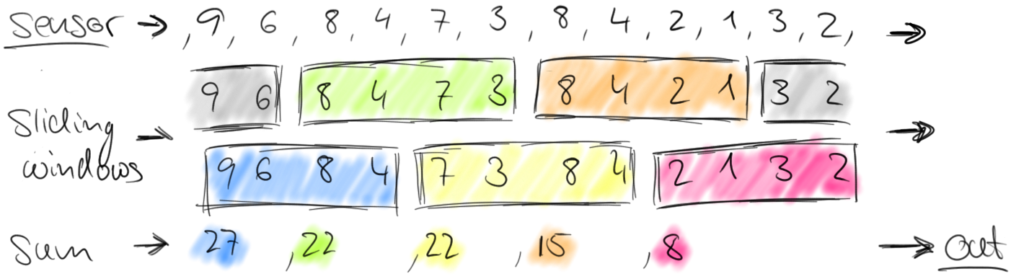
This is because each element of a stream must be processed by the same window operator that decides which windows the element should be added to. For many applications, a data stream needs to be grouped into multiple logical streams on each of which a window operator can be applied. Think for example about a stream of vehicle counts from multiple traffic sensors (instead of only one sensor as in our previous example), where each sensor monitors a different location. By grouping the stream by sensor id, we can compute windowed traffic statistics for each location in parallel.
The following figure shows tumbling windows that collect two elements over a stream of (sensorId, count) pair elements.
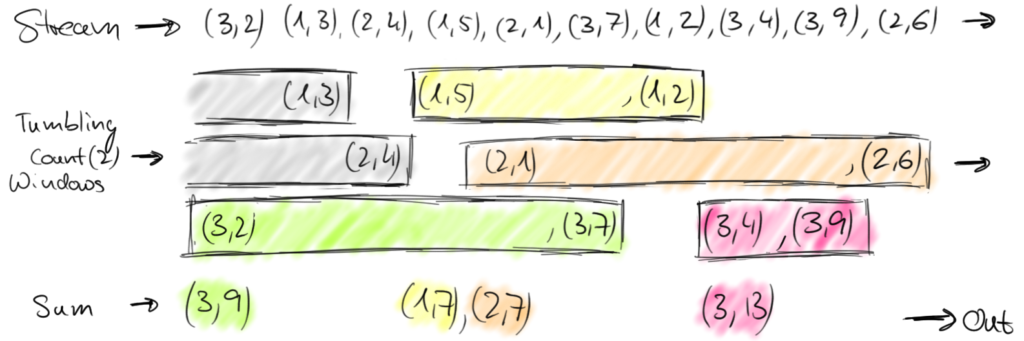
Generally speaking, a window defines a finite set of elements on an unbounded stream. This set can be based on time (as in our previous examples), element counts, a combination of counts and time, or some custom logic to assign elements to windows.
Streaming Joins
If we want to handle data from multiple tables, we use the JOIN operator in SQL. Similarly, if you want to handle data from multiple streams, there are two options. First is to join the two and create one stream while the second is to write patterns across multiple streams.
9. Why Stream Processing
https://towardsdatascience.com/introduction-to-stream-processing-5a6db310f1b4
https://medium.com/stream-processing/what-is-stream-processing-1eadfca11b97
10. Final considerations
We have entered an era where competitive advantage comes from analyzing, understanding, and responding to an organization’s data. When doing this, time is of the essence, and speed will decide the winners and losers.
Stream processing is required when data has to be processed fast and / or continuously, i.e. reactions have to be computed and initiated in real time. This requirement is coming more and more into every vertical. Many different frameworks and products are available on the market already.
Many use cases need fast, real-time decisions. Although it is possible to implement them using databases or batch processing, these technologies quickly introduce complexities because there is a fundamental impedance mismatch between the use cases and the tools employed. In contrast, streaming provides a much more natural model to think about, capture, and implement those real-time streaming use cases. Streaming SQL provides a simple yet powerful language to program streaming use cases.
The reality is that the value of most data degrades with time. It’s interesting to know that yesterday there was a traffic jam, or 10 fraud incidents, or 10 people who had heart attacks. From that knowledge, we can learn how to mitigate or prevent those incidents in the future. However, it is much better if we can gain those insights at the time they are occurring so that we can intervene and manage the situation.
The most popular Stream processing framework is Kafka. You can check my previous post here
11. Book
Designing Data-Intensive Applications
12. Influencers List
@martinkl
@paasdev
13. Links
The Log: What every software engineer should know about real-time data’s unifying abstraction
Oracle understanding stream analytics
Stream processing myths debunked – Six Common Streaming Misconceptions
Myth 1: There’s no streaming without batch (the Lambda Architecture)
Myth 2: Latency and Throughput: Choose One
Myth 3: Micro-batching means better throughput
Myth 4: Exactly once? Completely impossible.
Myth 5: Streaming only applies to “real-time”
Myth 6: So what? Streaming is too hard anyway.
The data processing evolution a potted history
Choosing a stream processor is challenging because there are many options to choose from and the best choice depends on end-user use cases.
How to choose stream processor