
How’s it going horse?
If you’re not familiar with Kafka, I suggest you have a look at my previous post “What is Kafka?” before.
This post is a collection of links, videos, tutorials, blogs and books that I found mixed with my opinion. The idea is that I’ll create a series of posts regarding Kafka Connect. Stay tuned!
Table of contents
1. What is Kafka Connect?
2. Concepts
3. Features
4. Why Kafka connect?
5. Courses
6. Books
7. Influencers List
8. Link
1. What is Kafka Connect?
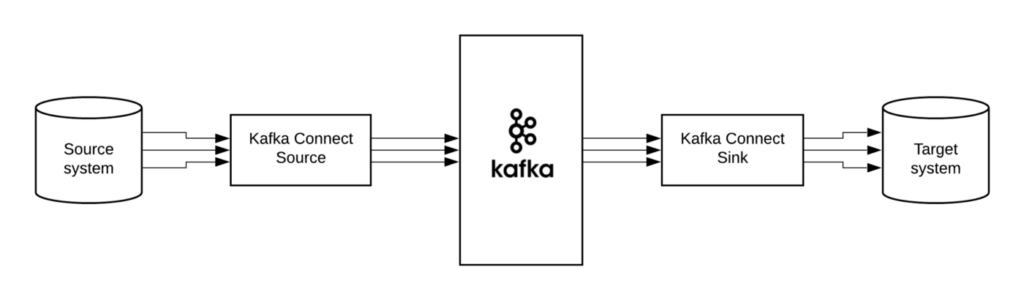
Kafka Connect (or Connect API) is a framework to import/export data from/to other systems. It was added in the Kafka 0.9.0.0 release and uses the Producer and Consumer API internally. The Connect framework itself executes so-called “connectors” that implement the actual logic to read/write data from other systems. The Connect API defines the programming interface that must be implemented to build a custom connector. Many open source and commercial connectors for popular data systems are available already. However, Apache Kafka itself does not include production ready connectors.
Connectors are meant to provide a simple way of connecting to external systems, only requiring a configuration file, while the scaling, distribution and persistence of state is handled by the framework for you. Connectors for common things like JDBC exist already at the Confluent Hub.
Official blog announcement and overview
For example;
Sometimes you need to process streams of data that are not in your Kafka cluster. These data may be located in a SQL database like SQL Server, MySQL or a simple CSV file. In order to process those data, you have to move them from your database to the Kafka cluster. To this end, you have some options and two of them are:
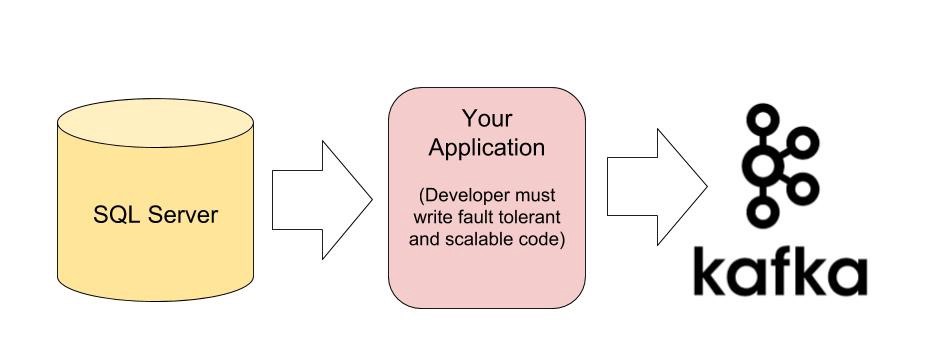
- Create an application that reads data from your source storage system and produces them to Kafka cluster.
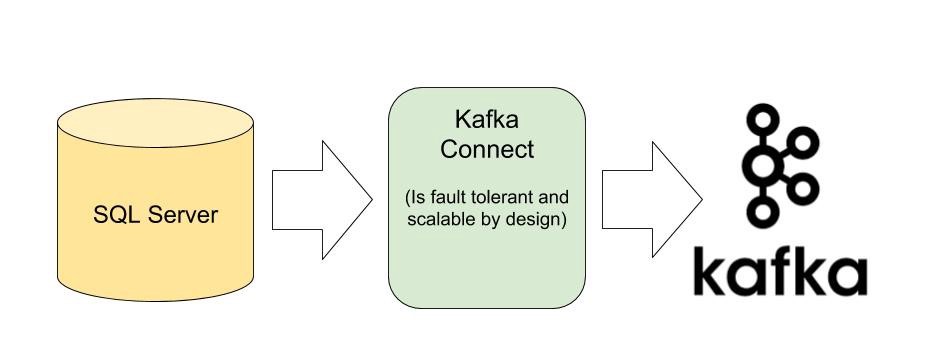
- Or use Kafka Connect to move your data easily from source storage system to your Kafka cluster.
If you choose the first option you need to write codes that move your data to the Kafka cluster. Your code must deal with the failure of your application (for example it must store the offset of the last record of tables that are moved to Kafka, so it can continue to copy the records that were not inserted into Kafka), scalability, polling and much more.
But if you choose the second option you can move data without writing any code. The Kafka Connect does the same job as the first option but in a scalable and fault-tolerant way. The process of copying data from a storage system and move it to Kafka Cluster is so common that Kafka Connect tool is created to address this problem.
Kafka connectors provide some powerful features. They can be easily configured to route unprocessable or invalid messages to a dead letter queue, apply Single Message Transforms before a message is written to Kafka by a source connector or before it is consumed from Kafka by a sink connector, integrate with Confluent Schema Registry for automatic schema registration and management, and convert data into types such as Avro or JSON. By leveraging existing connectors, developers can quickly create fault-tolerant data pipelines that reliably stream data from an external source into records in Kafka topics or from Kafka topics into an external sink, all with mere configuration and no code!
2. Concept
To efficiently discuss the inner workings of Kafka Connect, it is helpful to establish a few major concepts, and of course, I suggest a look in the official docs, here.
- Connectors – the high level abstraction that coordinates data streaming by managing tasks
- Tasks – the implementation of how data is copied to or from Kafka
- Workers – the running processes that execute connectors and tasks
- Converters – the code used to translate data between Connect and the system sending or receiving data
- Transforms – simple logic to alter each message produced by or sent to a connector
- Dead Letter Queue – how Connect handles connector errors
Each connector instance can break down its job into multiple tasks, thereby parallelizing the work of copying data and providing scalability. When a connector instance starts up a task, it passes along the configuration properties that each task will need. The task stores this configuration as well as the status and the latest offsets for the records it has produced or consumed externally in Kafka topics. Since the task does not store any state, tasks can be stopped, started, or restarted at any time. Newly started tasks will simply pick up the latest offsets from Kafka and continue on their merry way.
Workers are a physical concept. They are processes that run inside JVM. Your job in Kafka Connect concepts is called a connector. It is something like this:
- Copy records from table ‘accounts’ of my MySQL to Kafka topic ‘accounts’. It is called a source connector because you move data from external storage to Kafka.
- Copy each message from Kafka topic ‘product-events’ to a CSV file ‘myfile.csv’. It is called a sink connector because you move data from Kafka to external storage.
Kafka Connect uses workers for moving data. Workers are just simple Linux (or any other OS) processes. Kafka Connect can create a cluster of workers to make the copying data process scalable and fault tolerant. Workers need to store some information about their status, their progress in reading data from external storage and so on. To store that data, they use Kafka as their storage. Note that Kafka Connect cluster (which is a cluster of workers) is completely different from the Kafka cluster (which is a cluster of Kafka brokers). More workers mean that your copying process is more fault tolerant.
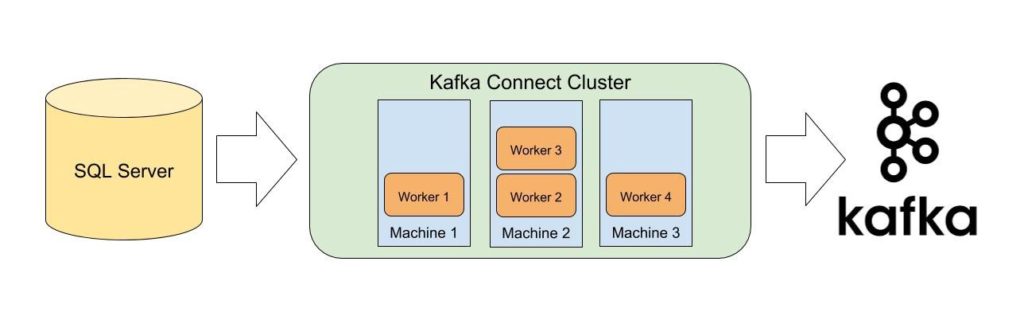
Standalone vs. Distributed Mode
There are two modes for running workers: standalone mode and distributed mode. You should identify which mode works best for your environment before getting started.
Standalone mode is useful for development and testing Kafka Connect on a local machine. It can also be used for environments that typically use single agents (for example, sending web server logs to Kafka).
Distributed mode runs Connect workers on multiple machines (nodes). These form a Connect cluster. Kafka Connect distributes running connectors across the cluster. You can add more nodes or remove nodes as your needs evolve.
Distributed mode is also more fault tolerant. If a node unexpectedly leaves the cluster, Kafka Connect automatically distributes the work of that node to other nodes in the cluster. And, because of Kafka Connect stores connector configurations, status, and offset information inside the Kafka cluster where it is safely replicated, losing the node where a Connect worker runs do not result in any lost data.
Converters are necessary to have a Kafka Connect deployment support a particular data format when writing to or reading from Kafka. Tasks use converters to change the format of data from bytes to a Connect internal data format and vice versa.
3. Features
A common framework for Kafka connectors
It standardizes the integration of other data systems with Kafka. Also, it simplifies connector development, deployment, and management.
Distributed and standalone modes
Scale up to a large, centrally managed service supporting an entire organization or scale down to development, testing, and small production deployments.
REST interface
By an easy to use REST API, we can submit and manage connectors to our Kafka Connect cluster.
Automatic offset management
However, Kafka Connect can manage the offset commit process automatically even with just a little information from connectors. Hence, connector developers do not need to worry about this error-prone part of connector development.
Distributed and scalable by default
It builds upon the existing group management protocol. And to scale up a Kafka Connect cluster we can add more workers.
Streaming/batch integration
We can say for bridging streaming and batch data systems, Kafka Connect is an ideal solution.
Transformations
Enable to make simple and lightweight modifications to individual messages
From Zero to Hero with Kafka Connect by Robin Moffatt
4. Why Kafka Connect
Auto-recovery After Failure
To each record, a “source” connector can attach arbitrary “source location” information which it passes to Kafka Connect. Hence, at the time of failure Kafka Connect will automatically provide this information back to the connector. In this way, it can resume where it failed. Additionally, auto recovery for “sink” connectors is even easier.
Auto-failover
Auto-failover is possible because the Kafka Connect nodes build a Kafka cluster. That means if suppose one node fails the work that it is doing is redistributed to other nodes.
Simple Parallelism
A connector can define data import or export tasks, especially which execute in parallel.
5. Courses
https://www.udemy.com/course/kafka-connect/
https://www.pluralsight.com/courses/kafka-connect-fundamentals
6. Books
Kafka: The Definitive Guide is the best option to start. There is a chapter “Kafka Connect”
Building Data Streaming Applications with Apache Kafka – there is a nice chapter “Deep dive into Kafka Connect”
7. Influencers List
@rmoff
@tlberglund