

How’s the form?
if you’re not familiar with Big Data or Data lake, I suggest you have a look on my previous post “What is Big Data?” and “What is data lake?” before.
This post is a collection of links, videos, tutorials, blogs and books that I found mixed with my opinion.
Table of contents
1. What is Kafka?
2. Architecture
3. History
4. Courses
5. Books
6. Influencers List
7. Link
1. What is Kafka?
In simple terms, Kafka is a messaging system that is designed to be fast, scalable, and durable. It is an open-source stream processing platform. Kafka is a distributed publish-subscribe messaging system that maintains feeds of messages in partitioned and replicated topics.
Wikipedia definition: Apache Kafka is an open-source stream-processing software platform developed by LinkedIn and donated to the Apache Software Foundation, written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. Its storage layer is essentially a “massively scalable pub/sub message queue designed as a distributed transaction log, making it highly valuable for enterprise infrastructures to process streaming data. Additionally, Kafka connects to external systems (for data import/export) via Kafka Connect and provides Kafka Streams, a Java stream processing library.
I Googled about and I found …
Kafka is designed for distributed high throughput systems. Kafka tends to work very well as a replacement for a more traditional message broker. In comparison to other messaging systems, Kafka has better throughput, built-in partitioning, replication and inherent fault-tolerance, which makes it a good fit for large-scale message processing applications.
Other …
Apache Kafka is a distributed publish-subscribe messaging system and a robust queue that can handle a high volume of data and enables you to pass messages from one end-point to another. Kafka is suitable for both offline and online message consumption. Kafka messages are persisted on the disk and replicated within the cluster to prevent data loss. Kafka is built on top of the ZooKeeper synchronization service. It integrates very well with Apache Storm and Spark for real-time streaming data analysis.
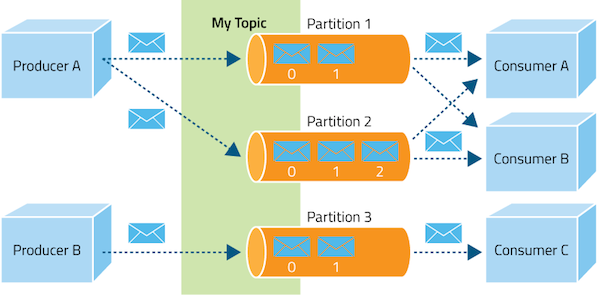
Producers
Producers produce messages to a topic of their choice. It is possible to attach a key to each message, in which case the producer guarantees that all messages with the same key will arrive to the same partition.
Consumers
Consumers read the messages of a set of partitions of a topic of their choice at their own pace. If the consumer is part of a consumer group, i.e. a group of consumers subscribed to the same topic, they can commit their offset. This can be important if you want to consume a topic in parallel with different consumers.
Topics and Logs
A topic is a feed name or category to which records are published. Topics in Kafka are always multi-subscriber — that is, a topic can have zero, one, or many consumers that subscribe to the data written to it. For each topic, the Kafka cluster maintains a partition log that looks like this:
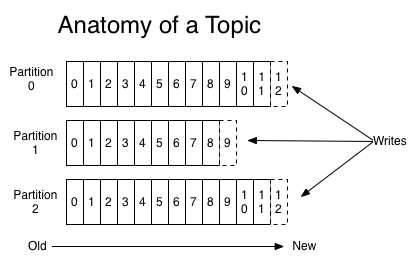
Topics are logs that receive data from the producers and store them across their partitions. Producers always write new messages at the end of the log.
Partitions
A topic may have many partitions so that it can handle an arbitrary amount of data. In the above diagram, the topic is configured into three partitions (partition{0,1,2}). Partition 0 has 13 offsets, Partition 1 has 10 offsets, and Partition 2 has 13 offsets.
Partition Offset
Each partitioned message has a unique sequence ID called an offset. For example, in Partition 1, the offset is marked from 0 to 9. The offset is the position in the log where the consumer last consumed or read a message.
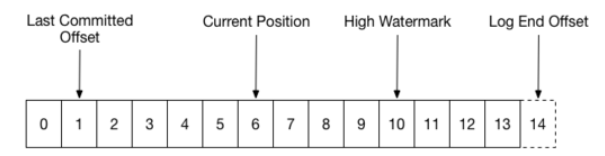
Distribution
The partitions of the log are distributed over the servers in the Kafka cluster with each server handling data and requests for a share of the partitions. Each partition is replicated across a configurable number of servers for fault tolerance.
Each partition has one server which acts as the “leader” and zero or more servers which act as “followers”. The leader handles all read and write requests for the partition while the followers passively replicate the leader. If the leader fails, one of the followers will automatically become the new leader. Each server acts as a leader for some of its partitions and a follower for others so load is well balanced within the cluster.
Geo-Replication
Kafka MirrorMaker provides geo-replication support for your clusters. With MirrorMaker, messages are replicated across multiple datacenters or cloud regions. You can use this in active/passive scenarios for backup and recovery; or in active/active scenarios to place data closer to your users, or support data locality requirements.
Replicas
Replicas are nothing but backups of a partition. If the replication factor of the above topic is set to 4, then Kafka will create four identical replicas of each partition and place them in the cluster to make them available for all its operations. Replicas are never used to read or write data. They are used to prevent data loss.
Messaging System
A messaging system is a system that is used for transferring data from one application to another so that the applications can focus on data and not on how to share it. Kafka is a distributed publish-subscribe messaging system. In a publish-subscribe system, messages are persisted in a topic. Message producers are called publishers and message consumers are called subscribers. Consumers can subscribe to one or more topic and consume all the messages in that topic.
Two types of messaging patterns are available − one is point to point and the other is publish-subscribe (pub-sub) messaging system. Most of the messaging patterns follow pub-sub.
- Point to Point Messaging System – In a point-to-point system, messages are persisted in a queue. One or more consumers can consume the messages in the queue, but a particular message can be consumed by a maximum of one consumer only. Once a consumer reads a message in the queue, it disappears from that queue. The typical example of this system is an Order Processing System, where each order will be processed by one Order Processor, but Multiple Order Processors can work as well at the same time.
- Publish-Subscribe Messaging System – In the publish-subscribe system, messages are persisted in a topic. Unlike point-to-point system, consumers can subscribe to one or more topic and consume all the messages in that topic. In the Publish-Subscribe system, message producers are called publishers and message consumers are called subscribers. A real-life example is Dish TV, which publishes different channels like sports, movies, music, etc., and anyone can subscribe to their own set of channels and get them whenever their subscribed channels are available
Brokers
Brokers are simple systems responsible for maintaining published data. Kafka brokers are stateless, so they use ZooKeeper for maintaining their cluster state. Each broker may have zero or more partitions per topic. For example, if there are 10 partitions on a topic and 10 brokers, then each broker will have one partition. But if there are 10 partitions and 15 brokers, then the starting 10 brokers will have one partition each and the remaining five won’t have any partition for that particular topic. However, if partitions are 15 but brokers are 10, then brokers would be sharing one or more partitions among them, leading to unequal load distribution among the brokers. Try to avoid this scenario.
Cluster
When Kafka has more than one broker, it is called a Kafka cluster. A Kafka cluster can be expanded without downtime. These clusters are used to manage the persistence and replication of message data.
Multi-tenancy
You can deploy Kafka as a multi-tenant solution. Multi-tenancy is enabled by configuring which topics can produce or consume data. There is also operations support for quotas. Administrators can define and enforce quotas on requests to control the broker resources that are used by clients. For more information, see the security documentation.
Zookeeper
ZooKeeper is used for managing and coordinating Kafka brokers. ZooKeeper is mainly used to notify producers and consumers about the presence of any new broker in the Kafka system or about the failure of any broker in the Kafka system. ZooKeeper notifies the producer and consumer about the presence or failure of a broker based on which producer and consumer makes a decision and starts coordinating their tasks with some other broker.
2. Architecture
Kafka has four core APIs:
- The Producer API allows an application to publish a stream of records to one or more Kafka topics.
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
- The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
- The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table.
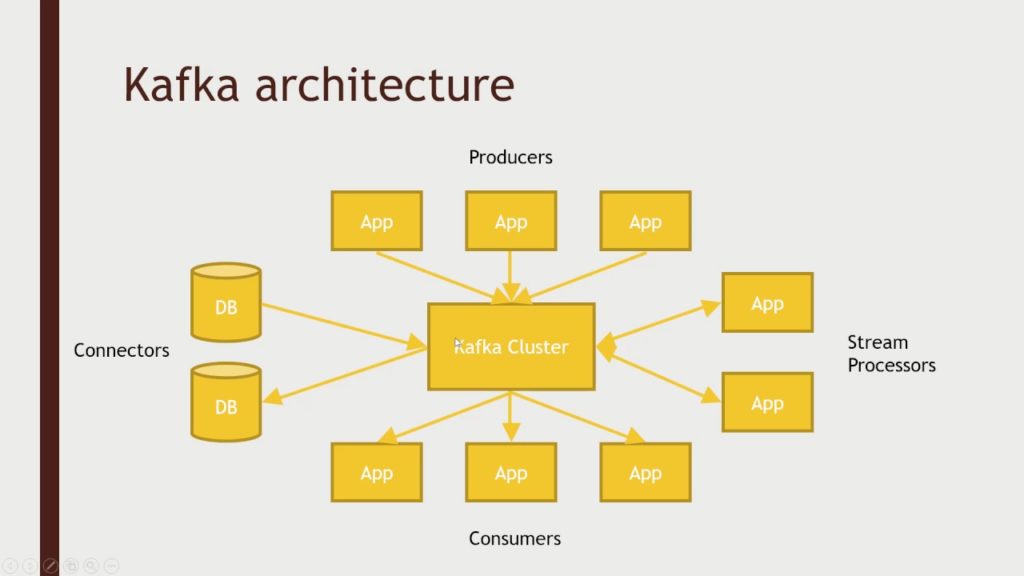
Apache describes Kafka as a distributed streaming platform that lets us:
- Publish and subscribe to streams of records.
- Store streams of records in a fault-tolerant way.
- Process streams of records as they occur.
Apache.org states that:
- Kafka runs as a cluster on one or more servers.
- The Kafka cluster stores a stream of records in categories called topics.
- Each record consists of a key, a value, and a timestamp.
3. History
Kafka was developed around 2010 at LinkedIn by a team that included Jay Kreps, Jun Rao, and Neha Narkhede. The problem they originally set out to solve was low-latency ingestion of large amounts of event data from the LinkedIn website and infrastructure into a lambda architecture that harnessed Hadoop and real-time event processing systems. The key was the “real-time” processing. At the time, there weren’t any solutions for this type of ingress for real-time applications.
There were good solutions for ingesting data into offline batch systems, but they exposed implementation details to downstream users and used a push model that could easily overwhelm a consumer. Also, they were not designed for the real-time use case.
Kafka was developed to be the ingestion backbone for this type of use case. Back in 2011, Kafka was ingesting more than 1 billion events a day. Recently, LinkedIn has reported ingestion rates of 1 trillion messages a day.
Why Kafka?
In Big Data, an enormous volume of data is used. But how are we going to collect this large volume of data and analyze that data? To overcome this, we need a messaging system. That is why we need Kafka. The functionalities that it provides are well-suited for our requirements, and thus we use Kafka for:
- Building real-time streaming data pipelines that can get data between systems and applications.
- Building real-time streaming applications to react to the stream of data.
Kafka can work with Flume/Flafka, Spark Streaming, Storm, HBase, Flink, and Spark for real-time ingesting, analysis and processing of streaming data. Kafka is a data stream used to feed Hadoop Big Data lakes. Kafka brokers support massive message streams for low-latency follow-up analysis in Hadoop or Spark. Also, Kafka Streaming (a subproject) can be used for real-time analytics.
Why is it so popular?
RedMonk.com published an article in February 2016 documenting some interesting stats around the “rise and rise” of a powerful asynchronous messaging technology called Apache Kafka.
https://redmonk.com/fryan/2016/02/04/the-rise-and-rise-of-apache-kafka/
Kafka has operational simplicity. Kafka is to set up and use, and it is easy to figure out how Kafka works. However, the main reason Kafka is very popular is its excellent performance. It is stable, provides reliable durability, has a flexible publish-subscribe/queue that scales well with N-number of consumer groups, has robust replication, provides producers with tunable consistency guarantees, and it provides preserved ordering at the shard level (i.e. Kafka topic partition). In addition, Kafka works well with systems that have data streams to process and enables those systems to aggregate, transform, and load into other stores. But none of those characteristics would matter if Kafka was slow. The most important reason Kafka is popular is Kafka’s exceptional performance.
Who Uses Kafka?
A lot of large companies who handle a lot of data use Kafka. LinkedIn, where it originated, uses it to track activity data and operational metrics. Twitter uses it as part of Storm to provide a stream processing infrastructure. Square uses Kafka as a bus to move all system events to various Square data centers (logs, custom events, metrics, and so on), outputs to Splunk, for Graphite (dashboards), and to implement Esper-like/CEP alerting systems. It’s also used by other companies like Spotify, Uber, Tumbler, Goldman Sachs, PayPal, Box, Cisco, CloudFlare, and Netflix.
Why Is Kafka So Fast?
Kafka relies heavily on the OS kernel to move data around quickly. It relies on the principals of zero copy. Kafka enables you to batch data records into chunks. These batches of data can be seen end-to-end from producer to file system (Kafka topic log) to the consumer. Batching allows for more efficient data compression and reduces I/O latency. Kafka writes to the immutable commit log to the disk sequential, thus avoiding random disk access and slow disk seeking. Kafka provides horizontal scale through sharding. It shards a topic log into hundreds (potentially thousands) of partitions to thousands of servers. This sharding allows Kafka to handle massive load.
Benefits of Kafka
Four main benefits of Kafka are:
- Reliability. Kafka is distributed, partitioned, replicated, and fault tolerant. Kafka replicates data and is able to support multiple subscribers. Additionally, it automatically balances consumers in the event of failure.
- Scalability. Kafka is a distributed system that scales quickly and easily without incurring any downtime.
- Durability. Kafka uses a distributed commit log, which means messages persists on disk as fast as possible providing intra-cluster replication, hence it is durable.
- Performance. Kafka has high throughput for both publishing and subscribing messages. It maintains stable performance even when dealing with many terabytes of stored messages.
Use Cases
Kafka can be used in many Use Cases. Some of them are listed below
- Metrics − Kafka is often used for operational monitoring data. This involves aggregating statistics from distributed applications to produce centralized feeds of operational data.
- Log Aggregation Solution − Kafka can be used across an organization to collect logs from multiple services and make them available in a standard format to multiple con-sumers.
- Stream Processing − Popular frameworks such as Storm and Spark Streaming read data from a topic, processes it, and write processed data to a new topic where it becomes available for users and applications. Kafka’s strong durability is also very useful in the context of stream processing.
4. Courses
https://www.udemy.com/apache-kafka-tutorial-for-beginners/
5. Book
Kafka: The Definitive Guide is the best option to start.
6. Influencers List
@nehanarkhede
@rmoff
@tlberglund
7. Link
Thorough Introduction to Apache Kafka
Kafka Architecture and Its Fundamental Concepts