
What’s the story Rory?
This blog post is part of my series of posts regarding “Kafka Connect Overview“.
If you’re not familiar with Kafka, I suggest you have a look at my previous post “What is Kafka?” before.
This post is a collection of links, videos, tutorials, blogs and books that I found mixed with my opinion.
Table of contents
1. Kafka Connect
2. Source & Sink Connectors
3. Standalone & Distributed
4. Converters & Transforms
5. Life cycle
6. Code
7. Books
8. Link
1. Kafka Connect
Kafka Connects goal of copying data between systems has been tackled by a variety of frameworks, many of them still actively developed and maintained. This section explains the motivation behind Kafka Connect, where it fits in the design space, and its unique features and design decisions
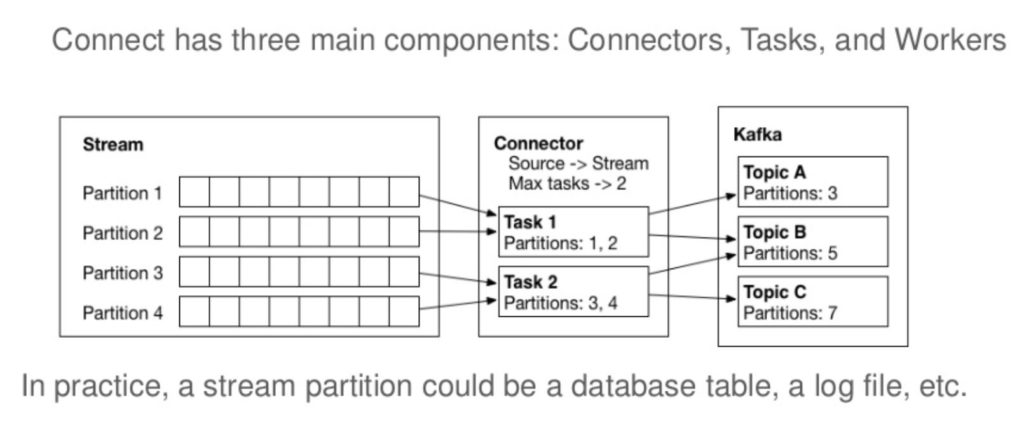
Kafka Connect has three major models in its design:
- Connector model
- Worker model
- Data model
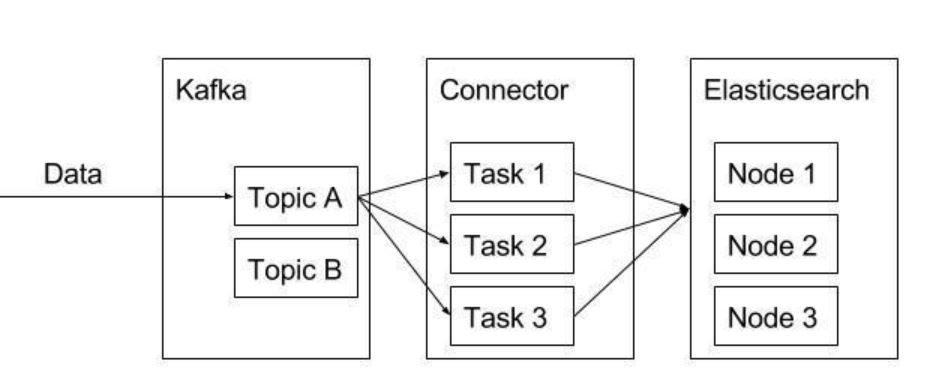
The connector model addresses three key user requirements. First, Kafka Connect performs broad copying by default by having users define jobs at the level of Connectors which then break the job into smaller Tasks. This two level scheme strongly encourages connectors to use configurations that encourage copying broad swaths of data since they should have enough inputs to break the job into smaller tasks. It also provides one point of parallelism by requiring Connectors to immediately consider how their job can be broken down into subtasks, and select an appropriate granularity to do so. Finally, by specializing source and sink interfaces, Kafka Connect provides an accessible connector API that makes it very easy to implement connectors for a variety of systems.
The worker model allows Kafka Connect to scale to the application. It can run scaled down to a single worker process that also acts as its own coordinator, or in clustered mode where connectors and tasks are dynamically scheduled on workers. However, it assumes very little about the process management of the workers, so it can easily run on a variety of cluster managers or using traditional service supervision. This architecture allows scaling up and down, but Kafka Connect’s implementation also adds utilities to support both modes well. The REST interface for managing and monitoring jobs makes it easy to run Kafka Connect as an organization-wide service that runs jobs for many users. Command line utilities specialized for ad hoc jobs make it easy to get up and running in a development environment, for testing, or in production environments where an agent-based approach is required.
The data model addresses the remaining requirements. Many of the benefits come from coupling tightly with Kafka. Kafka serves as a natural buffer for both streaming and batch systems, removing much of the burden of managing data and ensuring delivery from connector developers. Additionally, by always requiring Kafka as one of the endpoints, the larger data pipeline can leverage the many tools that integrate well with Kafka. This allows Kafka Connect to focus only on copying data because a variety of stream processing tools are available to further process the data, which keeps Kafka Connect simple, both conceptually and in its implementation. This differs greatly from other systems where ETL must occur before hitting a sink. In contrast, Kafka Connect can bookend an ETL process, leaving any transformation to tools specifically designed for that purpose. Finally, Kafka includes partitions in its core abstraction, providing another point of parallelism
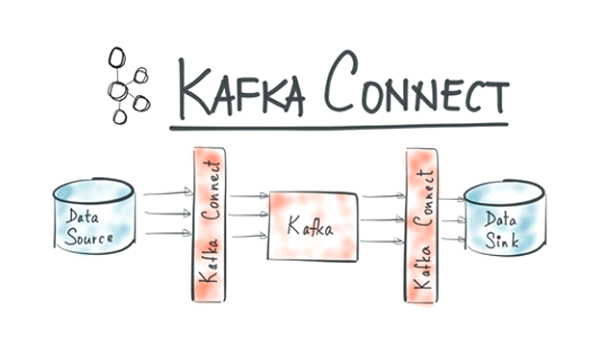
In simples words
Kafka Connect is a distributed, scale, fault-tolerant service designed to reliably stream data between Kafka and other data systems. Data is produced from a source and consumed to a sink.
Connect tracks the offset that was last consumed for a source, to restart task at the correct starting point after a failure. These offsets are different from Kafka offsets, they are based on the sourse system like database, file, etc.
In standalone mode, the source offset is tracked in a local file and in a distributed mode, the source offset is tracked in a Kafka topic.
2. Source & Sink connectors
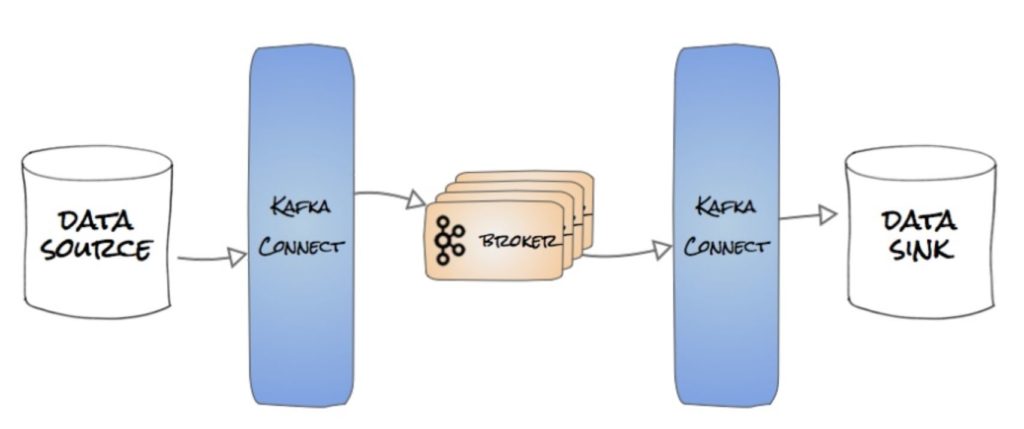
Producers and Consumers provide complete flexibility to send any data to Kafka or process in any way. This flexibility means you do everything yourself.
Kafka Connect’s simple frameworks allows;
- developers to create connectors that copy data to or from others systems.
- Operators to use said connectors just by writing configuration files and submitting them to Connect. (No code)
- Community and 3rd-party engineers to build reliable plugins for common data sources and sinks.
- Deployments to deliver fault-tolerant and automated load balance out-of-the-box.
And the frameworks do the hard work;
- Serialization and deserialization.
- Schema registry integration.
- Fault-tolerant and failover.
- Partitioning and scale-out.
- And let the developers focus on domain specific details.
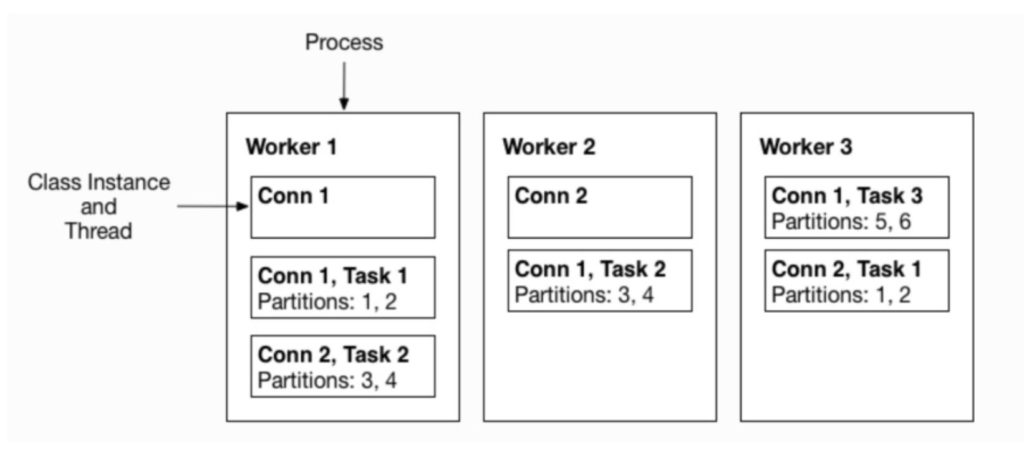
3. Standalone & Distributed
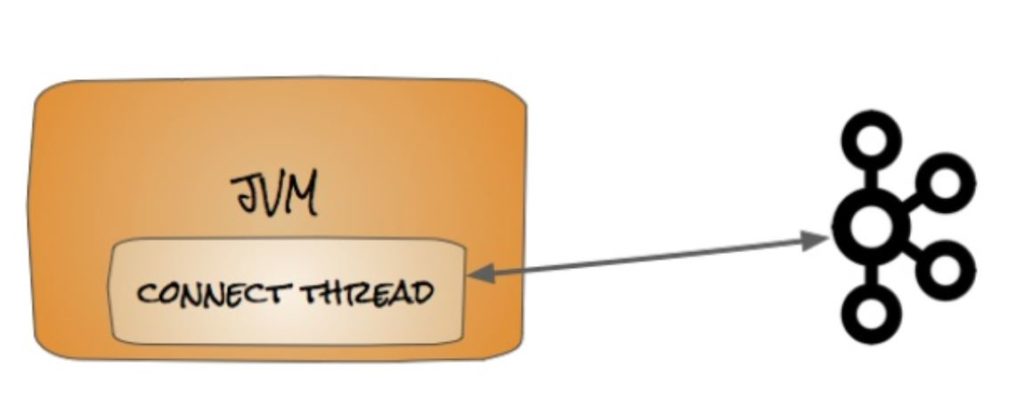
In standalone mode we have a source or a Sink and a Kafka broker, when we deploy Kafka connect in the standalone we actually need to pass a configuration file containing all the connection properties that we need to run. So standalone’s main way of providing configuration to our connector is by using properties files and not the Rest API.
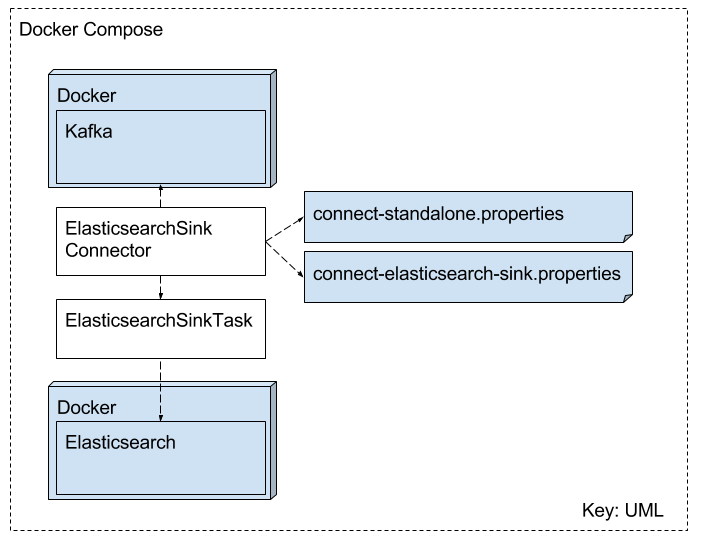
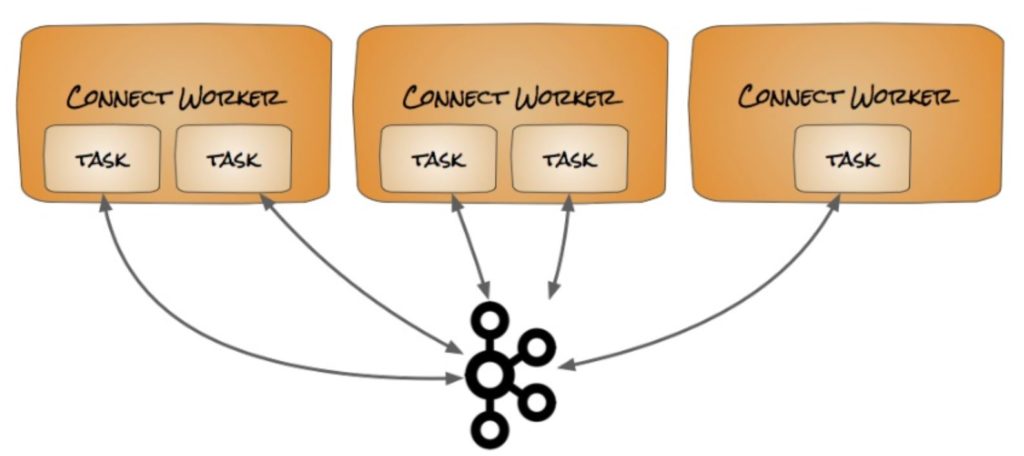
In the distributed mode we usually have more than one worker, since these workers can be in different machines or containers they can not share the same storage space, so a properties file is out of the question. Instead kafka connect in distributed mode leverage kafka topics in order to sink between themselves.
4. Converters & Transforms
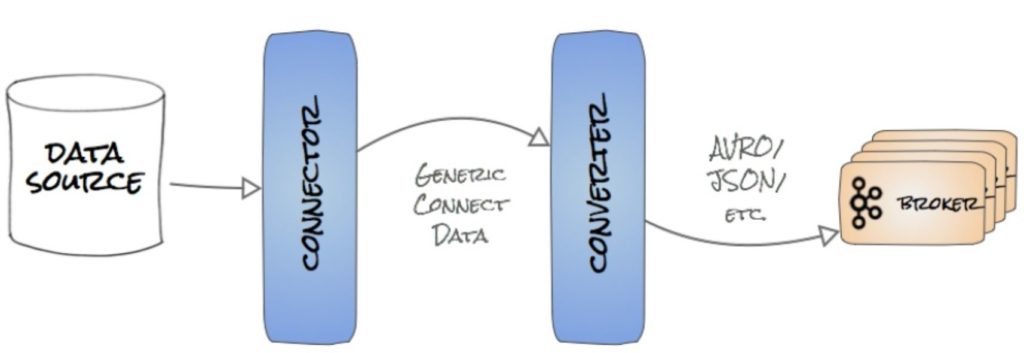
Pluggable API to convert data between native formats and Kafka. Just like the name says. Converters are used to come for data from a format to another.
In the Source connectors converters are invoked after the data has been fetched from the source and before it is published to kafka.
In the Sink connectors converters are invoked after the data has been consumed from Kafka and before it is stored in the sink.
Apache Kafka ships with Json Converter.
![]()
Transform is a simple operation that can be applied in the message level.
There’s a nice blog post about Single message transforms here.
Single message transforms SMT modify events before storing in Kafka, mask sensitive information, add identifiers, tag events, remove unnecessary columns and more, modify events going out of Kafka, route high priority events to faster datastore, cast data types to match destination and more.

5. Life cycle
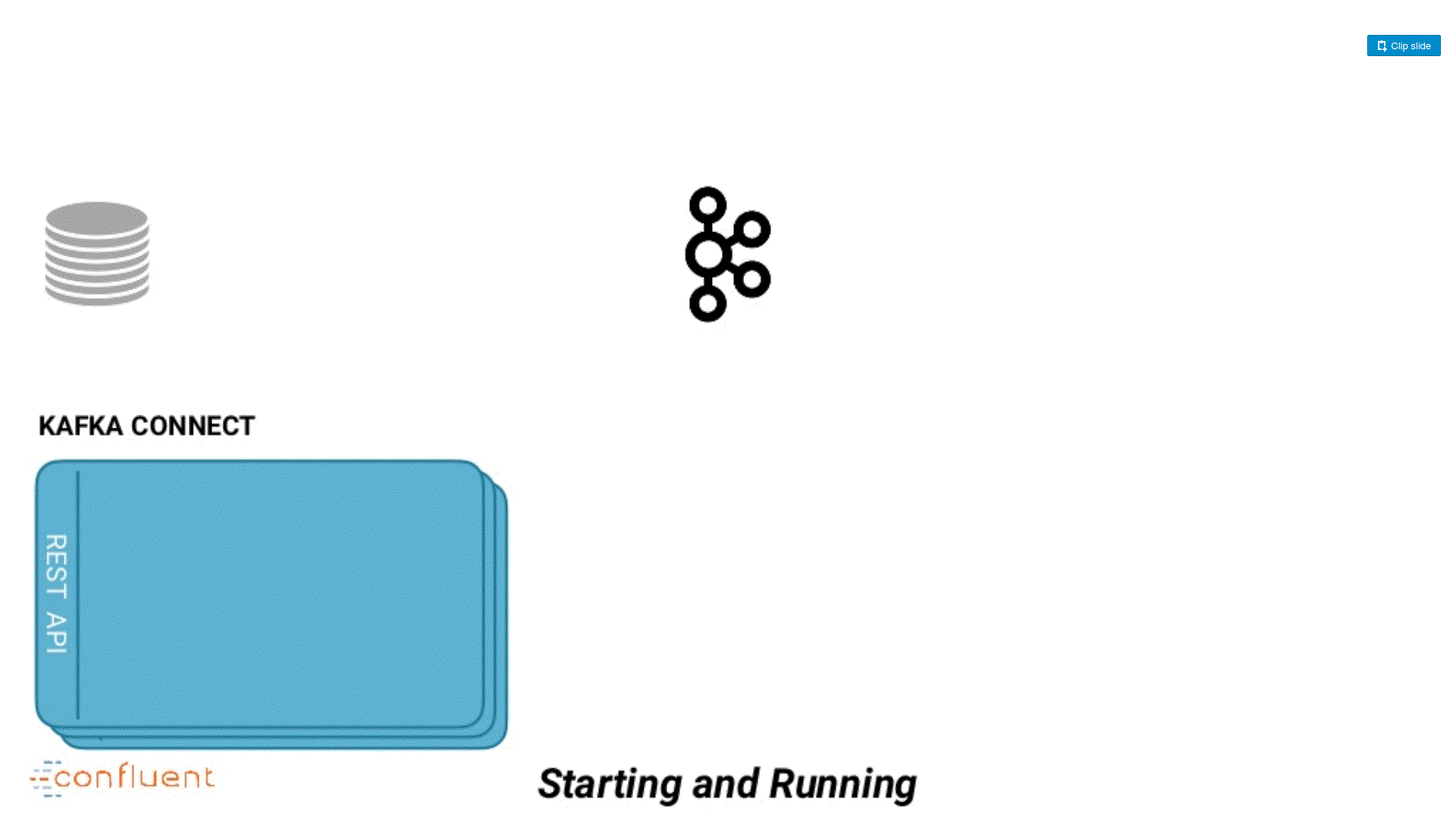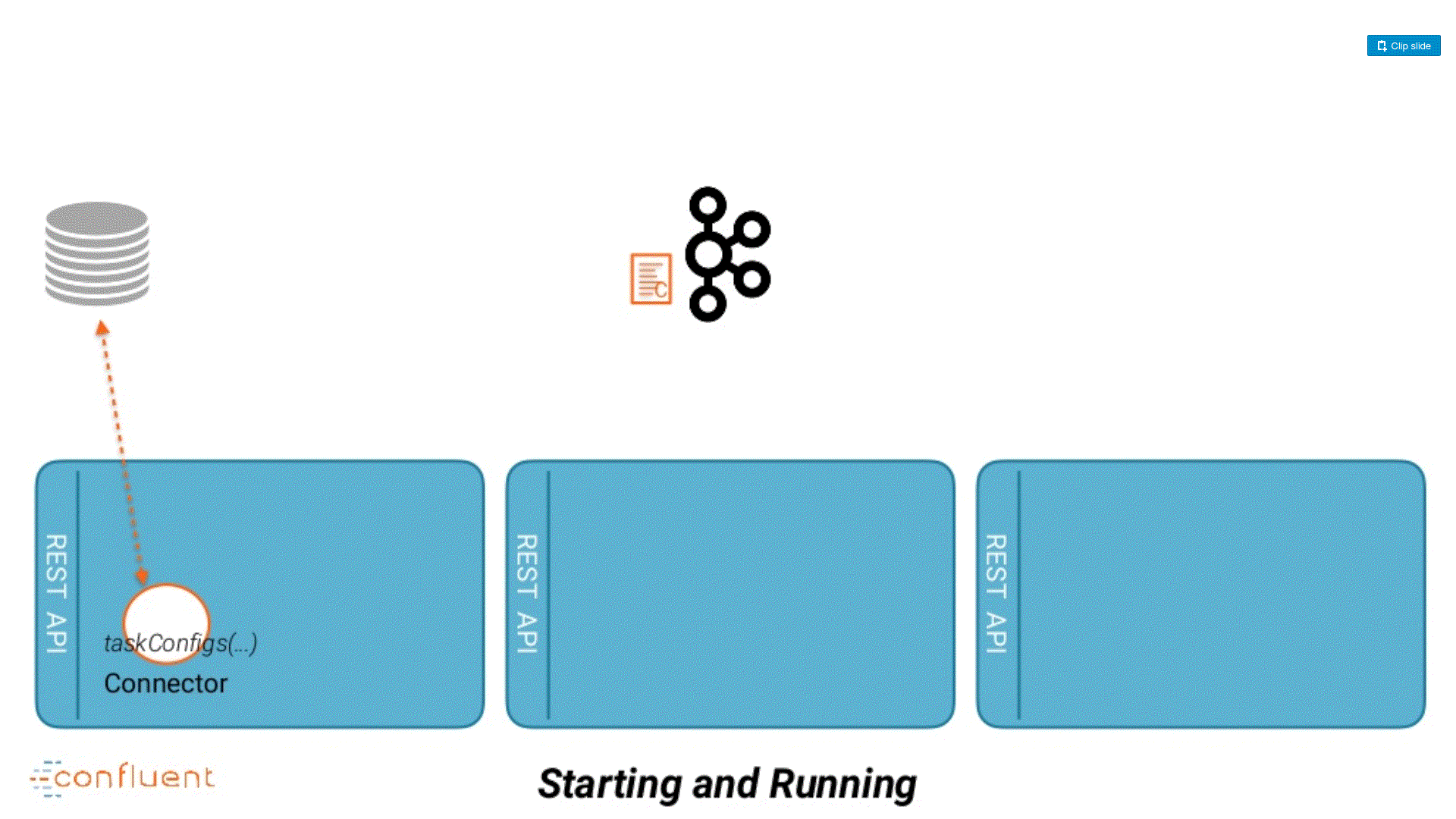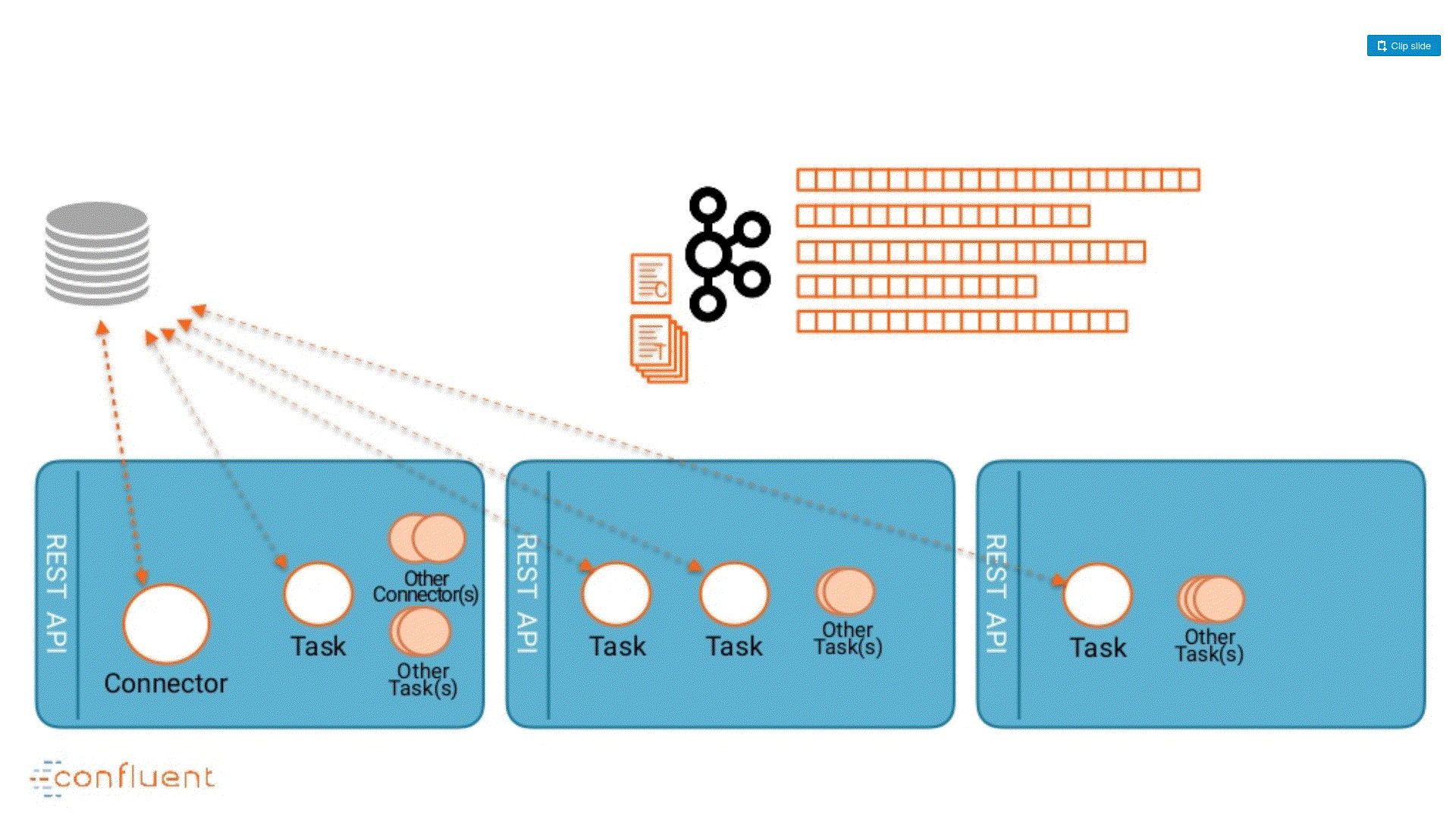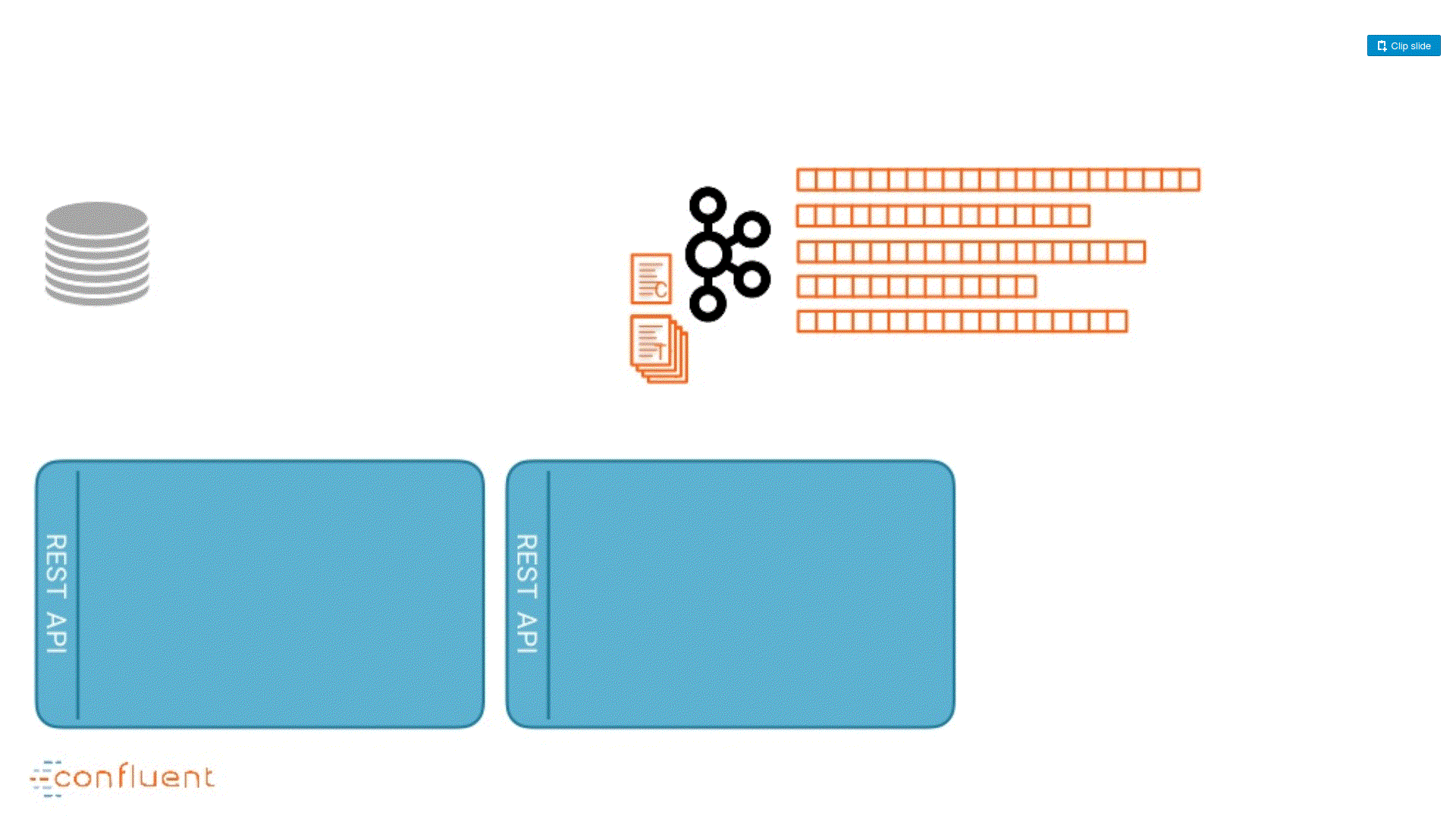
I build this animation using the slides from (Randall Hauch, Confluent) Kafka Summit SF 2018 here.
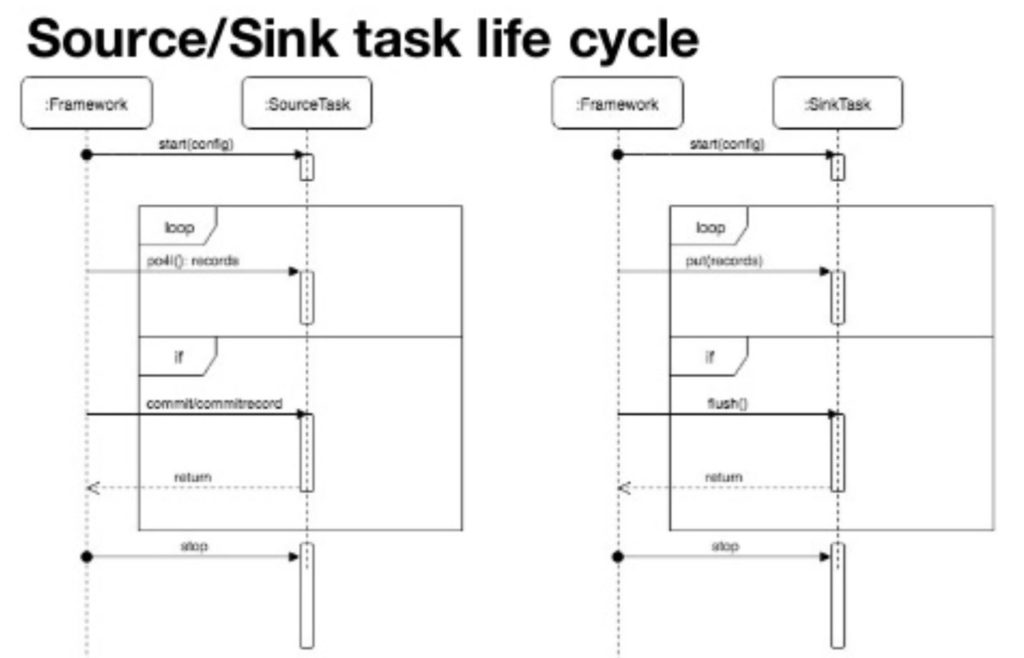
Sequence diagram
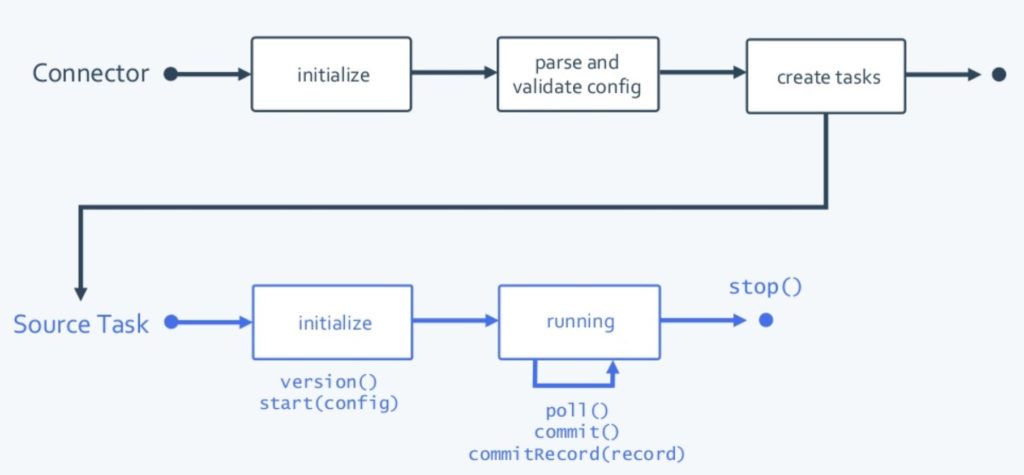
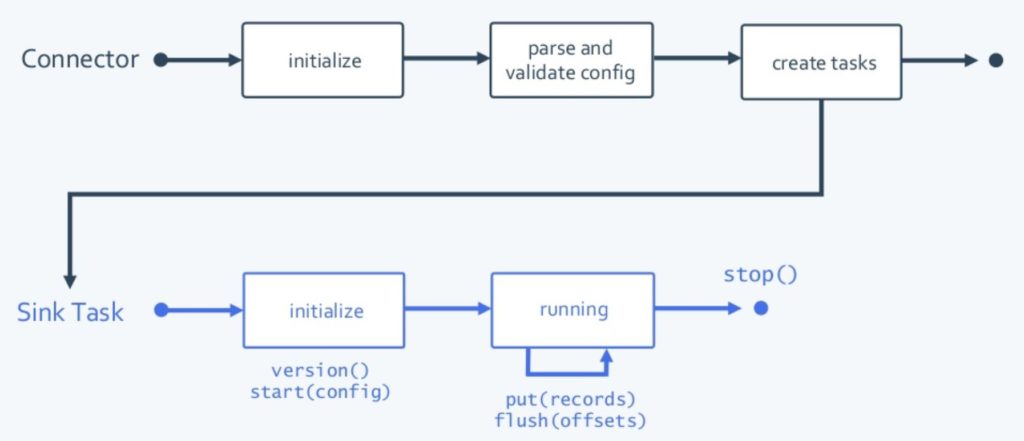
6. Code
Confluent makes available a code example that you can found here.
7. Books
Modern Big Data Processing with Hadoop
8. Links
https://docs.confluent.io/current/connect/managing/confluent-hub/component-archive.html
https://docs.confluent.io/current/connect/design.html
https://www.confluent.io/blog/kafka-connect-deep-dive-error-handling-dead-letter-queues/