
How’s it going horse?
If you’re not familiar with Kafka, I suggest you have a look at my previous post “What is Kafka?” before.
This blog is just a quick review of Kafka Producer and Consumer.
Table of contents
1. Producer
2. Consumer
3. Link
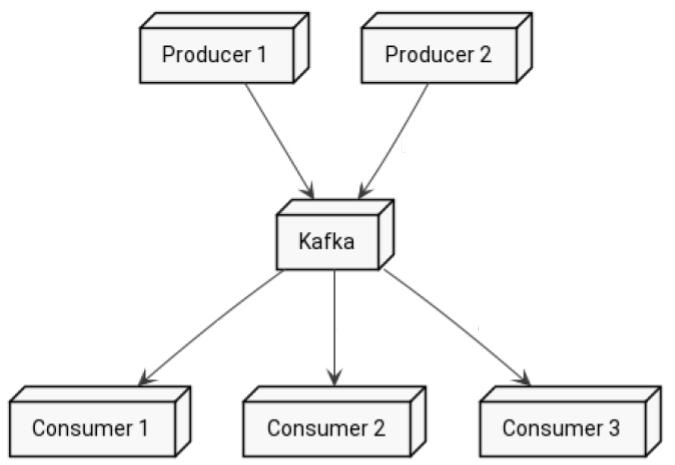
Kafka has a notion of producer and consumer. The first one pushes messages to Kafka, while the second one fetches them.
Official docs;
Producer
Consumer
1. Producer
The primary role of a Kafka producer is to take producer properties & record as inputs and write it to an appropriate Kafka broker. Producers serialize, partitions, compresses and load balances data across brokers based on partitions.
In order to send the producer record to an appropriate broker, the producer first establishes a connection to one of the bootstrap servers. The bootstrap-server returns list of all the brokers available in the clusters and all the metadata details like topics, partitions, replication factor and so on. Based on the list of brokers and metadata details the producer identifies the leader broker that hosts the leader partition of the producer record and writes to the broker.
Important Producer Settings:
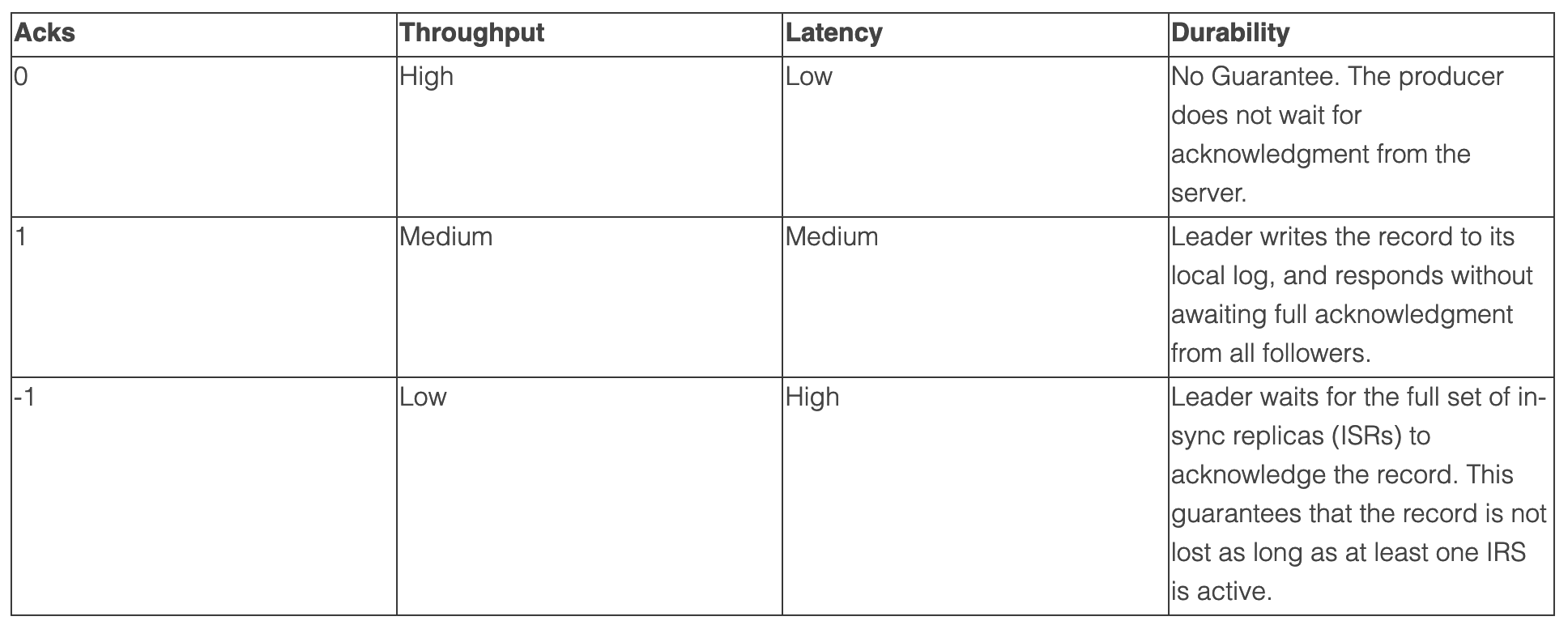
Acks
The acks setting specifies acknowledgements that the producer requires the leader to receive before considering a request complete. This setting defines the durability level for the producer.
Max.in.flight.requests.per.connection
The maximum number of unacknowledged requests the client will send on a single connection before blocking. If this setting is greater than 1, pipelining is used when the producer sends the grouped batch to the broker. This improves throughput, but if there are failed sends there is a risk of out-of-order delivery due to retries (if retries are enabled). Note also that excessive pipelining reduces throughput.
Compression.type
Compression is an important part of a producer’s work, and the speed of different compression types differs a lot.
To specify compression type, use the compression.type property. It accepts standard compression codecs (‘gzip’, ‘snappy’, ‘lz4’), as well as ‘uncompressed’ (the default, equivalent to no compression), and ‘producer’ (uses the compression codec set by the producer).
Compression is handled by the user thread. If compression is slow it can help to add more threads. In addition, batching efficiency impacts the compression ratio: more batching leads to more efficient compression.
Batch.size
Larger batches typically have better compression ratios and higher throughput, but they have higher latency.
Linger.ms
There is no simple guideline for setting linger.ms values; you should test settings on specific use cases. For small events (100 bytes or less), this setting does not appear to have much impact.
Kafka tutorial advanced producers
Code
1 2 3 4 5 | <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>${kafka.version}</version> </dependency> |
Simple Java Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | package com.codingharbour.kafka.producer; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.Producer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.common.serialization.StringSerializer; import java.time.Instant; import java.util.Properties; public class SimpleKafkaProducer { public static void main(String[] args) { //create kafka producer Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); Producer<String, String> producer = new KafkaProducer<>(properties); //prepare the record String recordValue = "Current time is " + Instant.now().toString(); System.out.println("Sending message: " + recordValue); ProducerRecord<String, String> record = new ProducerRecord<>("java_topic", null, recordValue); //produce the record producer.send(record); producer.flush(); //close the producer at the end producer.close(); } } |
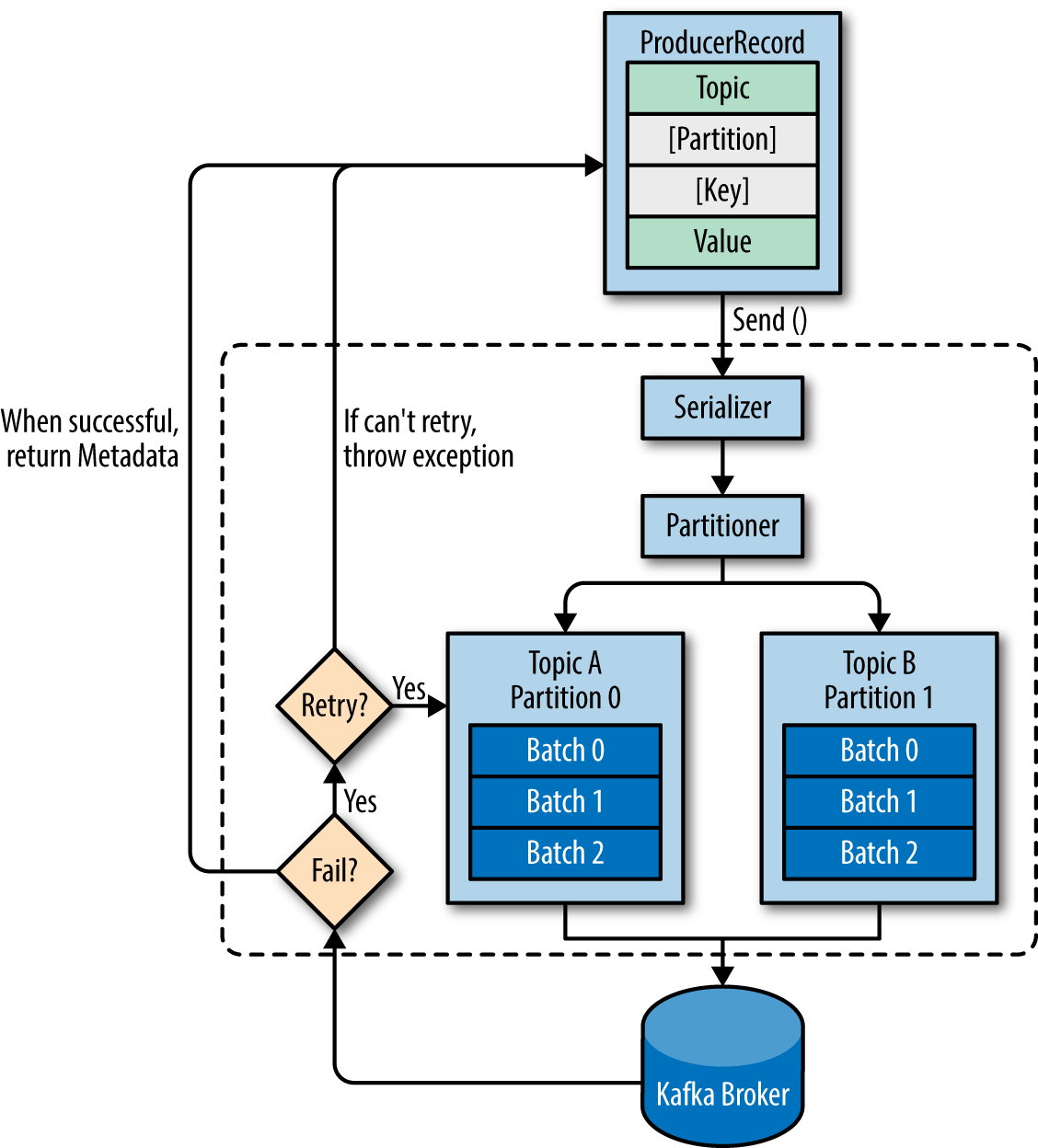
High-level overview of Kafka producer components – Kafka the Definitive Guide Book
2. Consumer
The primary role of a Kafka consumer is to read data from an appropriate Kafka broker. In order to understand how to read data from Kafka, you first need to understand its consumers and consumer groups.
A consumer group is a group of consumers that share the same group id. When a topic is consumed by consumers in the same group, every record will be delivered to only one consumer. As the official documentation states: “If all the consumer instances have the same consumer group, then the records will effectively be load-balanced over the consumer instances.”
This way you can ensure parallel processing of records from a topic and be sure that your consumers won’t be stepping on each other toes.
Each topic consists of one or more partitions. When a new consumer is started it will join a consumer group and Kafka will then ensure that each partition is consumed by only one consumer from that group.
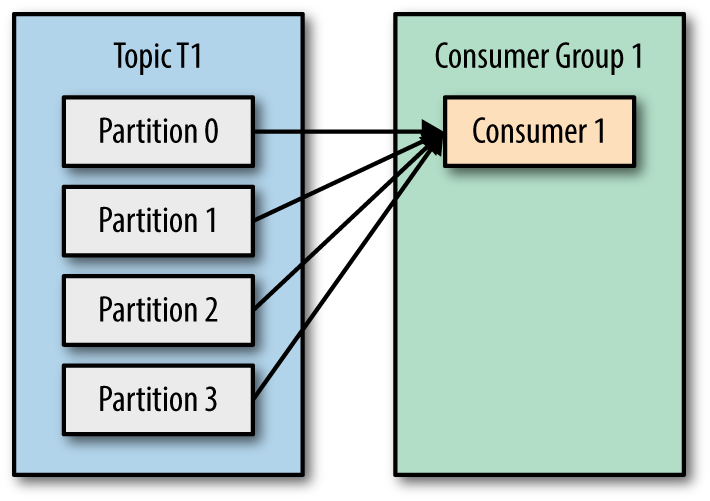
Kafka the Definitive Guide Book
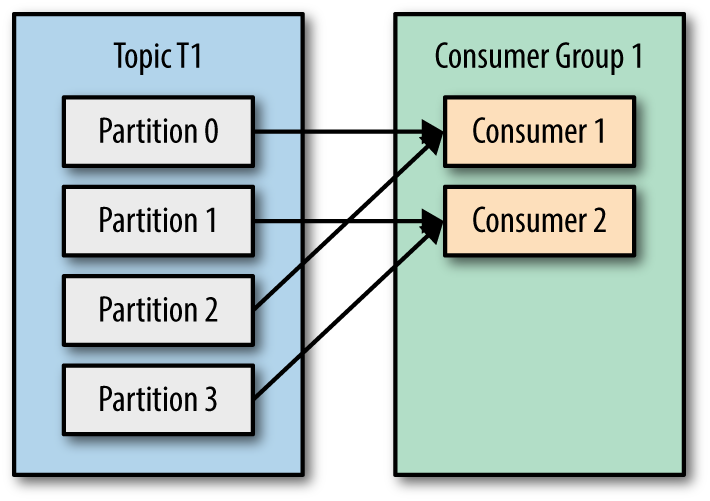
Kafka the Definitive Guide Book
You can have many consumers reading the same records from the topic, as long as they all have different group ids.
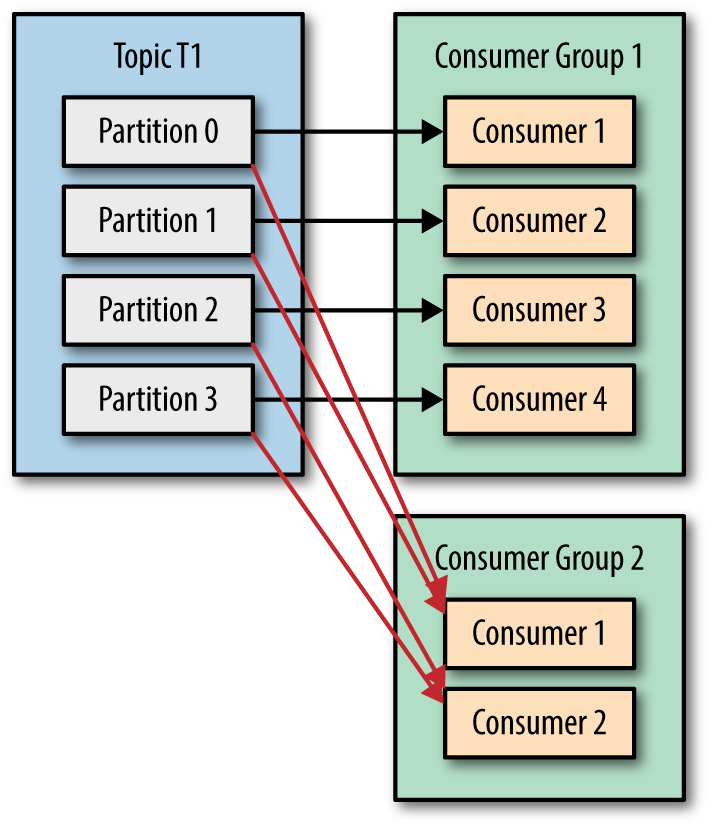
Kafka the Definitive Guide Book
Consumer groups provide the following advantages:
- Each instance receives messages from one or more partitions (which are “automatically” assigned to it), and the same messages won’t be received by the other instances (assigned to different partitions). In this way, we can scale the number of the instances up to the number of the partitions (having one instance reading only one partition). In this case, a new instance joining the group is in an idle state without being assigned to any partition.
- Having instances as part of different consumer groups means providing a publish/subscribe pattern in which the messages from partitions are sent to all the instances across the different groups. Inside the same consumer group, the rules are as shown in the secondi image, but across different groups, the instances receive the same messages (as shown in the third image). This is useful when the messages inside a partition are of interest for different applications that will process them in different ways. We want all the interested applications to receive all the same messages from the partition.
- Another advantage of consumer groups is the rebalancing feature. When an instance joins a group, if enough partitions are available (that is, the limit of one instance per partition hasn’t been reached), a rebalancing starts. The partitions are reassigned to the current instances, plus the new one. In the same way, if an instance leaves a group, the partitions are reassigned to the remaining instances.
- Offset commits are managed automatically.
Code
Simple Java Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | package com.codingharbour.kafka.consumer; import org.apache.kafka.clients.consumer.Consumer; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.serialization.StringDeserializer; import java.time.Duration; import java.util.Collections; import java.util.Properties; public class SimpleKafkaConsumer { public static void main(String[] args) { //create kafka consumer Properties properties = new Properties(); properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); properties.put(ConsumerConfig.GROUP_ID_CONFIG, "my-first-consumer-group"); properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); Consumer<String, String> consumer = new KafkaConsumer<>(properties); //subscribe to topic consumer.subscribe(Collections.singleton("java_topic")); //poll the record from the topic while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100)); for (ConsumerRecord<String, String> record : records) { System.out.println("Message received: " + record.value()); } consumer.commitAsync(); } } } |
3. Links
https://www.linkedin.com/pulse/kafka-producer-overview-sylvester-daniel
https://www.linkedin.com/pulse/kafka-producer-delivery-semantics-sylvester-daniel/
https://www.linkedin.com/pulse/kafka-consumer-overview-sylvester-daniel/
https://www.linkedin.com/pulse/kafka-consumer-delivery-semantics-sylvester-daniel