
![]()
Alright, Boyo?
if you’re not familiar with Big Data, I suggest you have a look on my post “What is Big Data?
” before.
This post is a collection of links, videos, tutorials, blogs and books that I found mixed with my opinion.
Table of contents
1. What is Hadoop?
2. Architecture
3. History
4. Courses
5. Books
6. Influence’s List
7. Podcasts
8. Newsletters
9. Links
1. What is Hadoop?
Hadoop is a framework that allows you to first store Big Data in a distributed environment, so that, you can process it parallelly.
Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware. Hadoop is an Apache top-level project being built and used by a global community of contributors and users. It is licensed under the Apache License 2.0.
According to the definition of 3V’s of big data, Apache Hadoop came to solve these problems.
The first problem is storing Big data.
HDFS provides a distributed way to store Big data. Your data is stored in blocks across the DataNodes and you can specify the size of blocks. Basically, if you have 512MB of data and you have configured HDFS such that, it will create 128 MB of data blocks. So HDFS will divide data into 4 blocks as 512/128=4 and store it across different DataNodes, it will also replicate the data blocks on different DataNodes. Now, as we are using commodity hardware, hence storing is not a challenge.
It also solves the scaling problem. It focuses on horizontal scaling instead of vertical scaling. You can always add some extra data nodes to HDFS cluster as and when required, instead of scaling up the resources of your DataNodes.
The second problem was storing a variety of data.
With HDFS you can store all kinds of data whether it is structured, semi-structured or unstructured. Since in HDFS, there is no pre-dumping schema validation. And it also follows write once and read many models. Due to this, you can just write the data once and you can read it multiple times for finding insights.
The third challenge was accessing & processing the data faster.
This is one of the major challenges with Big Data. In order to solve it, we move processing to data and not data to processing. What does it mean? Instead of moving data to the master node and then processing it. In MapReduce, the processing logic is sent to the various slave nodes & then data is processed parallely across different slave nodes. Then the processed results are sent to the master node where the results are merged and the response is sent back to the client.
In YARN architecture, we have ResourceManager and NodeManager. ResourceManager might or might not be configured on the same machine as NameNode. But, NodeManagers should be configured on the same machine where DataNodes are present.
2. Architecture
We can divide Hadoop in some modules;
A. Hadoop Common: contains libraries and utilities needed by other Hadoop modules
B. Hadoop Distributed File System (HDFS): a distributed file-system that stores data on the commodity machines, providing very high aggregate bandwidth across the cluster
C. Hadoop MapReduce: a programming model for large scale data processing
D. Hadoop YARN: a resource-management platform responsible for managing compute resources in clusters and using them for scheduling of users’ applications
A. Hadoop Common
Refers to the collection of common utilities and libraries that support other Hadoop modules. It is an essential part or module of the Apache Hadoop Framework, along with the Hadoop Distributed File System (HDFS), Hadoop YARN and Hadoop MapReduce.
B. How the Hadoop Distributed File System (HDFS) works
Hadoop has a file system that is much like the one on your desktop computer, but it allows us to distribute files across many machines. HDFS organizes information into a consistent set of file blocks and storage blocks for each node. In the Apache distribution, the file blocks are 64MB and the storage blocks are 512 KB. Most of the nodes are data nodes, and there are also copies of the data. Name nodes exist to keep track of where all the file blocks reside.
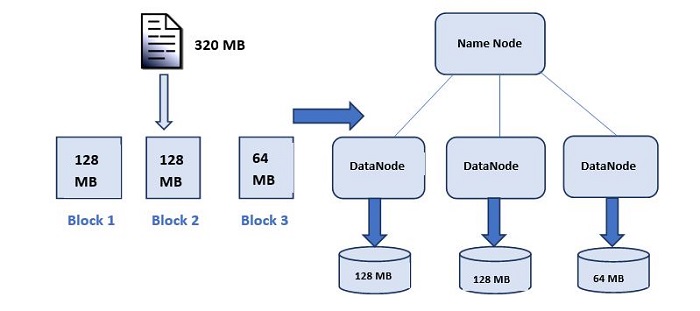
Each node in a Hadoop instance typically has a single namenode, and a cluster of datanodes form the HDFS cluster. The situation is typical because each node does not require a datanode to be present. Each datanode serves up blocks of data over the network using a block protocol specific to HDFS. The file system uses the TCP/IP layer for communication. Clients use Remote procedure call (RPC) to communicate with each other. With the default replication value, 3, data is stored on three nodes: two on the same rack, and one on a different rack. Data nodes can talk to each other to rebalance data, to move copies around, and to keep the replication of data high.
The HDFS file system includes a so-called secondary namenode, which misleads some people into thinking that when the primary namenode goes offline, the secondary namenode takes over. In fact, the secondary namenode regularly connects with the primary namenode and builds snapshots of the primary namenode’s directory information, which the system then saves to local or remote directories.
File access can be achieved through the native Java API, the Thrift API, to generate a client in the language of the users’ choosing ( Java, Python, Scala, …), the command-line interface, or browsed through the HDFS-UI web app over HTTP.
NameNode
Maintains and Manages DataNodes.
Records Metadata i.e. information about data blocks e.g. location of blocks stored, the size of the files, permissions, hierarchy, etc.
Receives status and block report from all the DataNodes.
DataNode
Slave daemons. It sends signals to NameNode.
Stores actual It stores in data blocks.
Serves read and write requests from the clients.
C. How MapReduce works
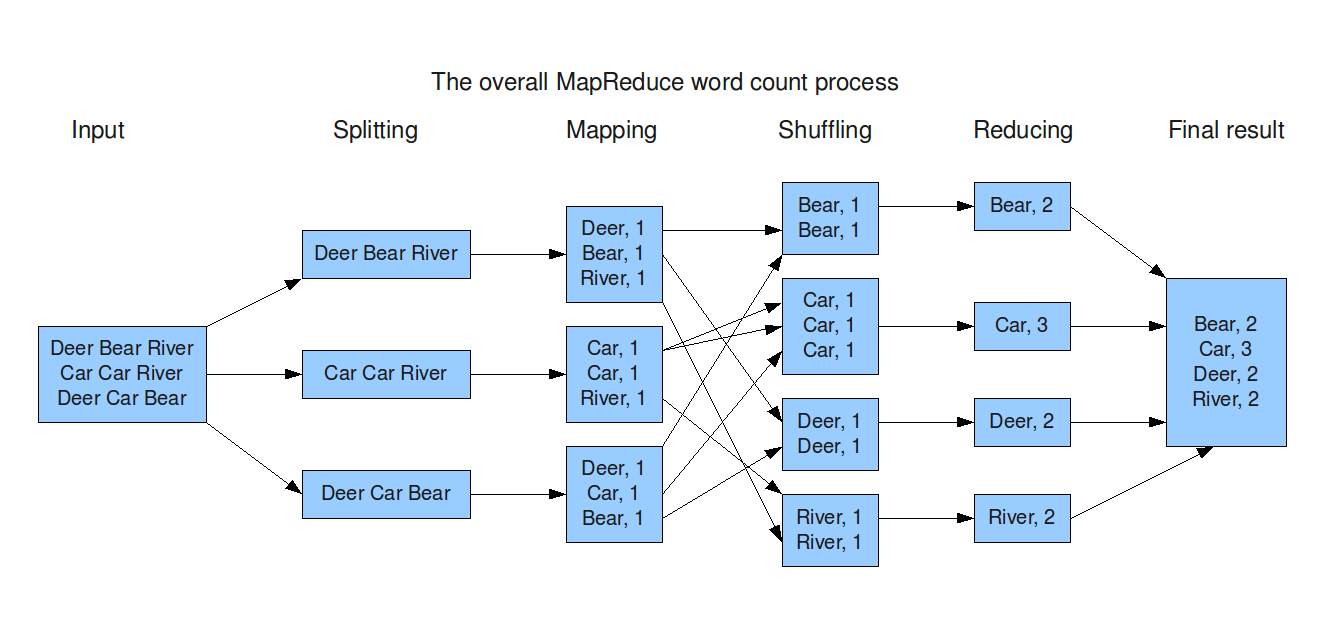
Map Reduce is a really powerful programming model that was built by some smart guys at Google. It helps to process really large sets of data on a cluster using a parallel distributed algorithm.
As the name suggests, there are two steps in the MapReduce process—map and reduce. Let’s say you start with a file containing all the blog entries about big data in the past 24 hours and want to count how many times the words Hadoop, Big Data, and Greenplum are mentioned. First, the file gets split up on HDFS. Then, all participating nodes go through the same map computation for their local dataset—they count the number of times these words show up. When the map step is complete, each node outputs a list of key-value pairs.
Once mapping is complete, the output is sent to other nodes as input for the reduce step. Before reduce runs, the key-value pairs are typically sorted and shuffled. The reduce phase then sums the lists into single entries for each word.
Above the file systems comes the MapReduce engine, which consists of one JobTracker, to which client applications submit MapReduce jobs. The JobTracker pushes work out to available TaskTracker nodes in the cluster, striving to keep the work as close to the data as possible.
With a rack-aware file system, the JobTracker knows which node contains the data, and which other machines are nearby. If the work cannot be hosted on the actual node where the data resides, priority is given to nodes in the same rack. This reduces network traffic on the main backbone network.
If a TaskTracker fails or times out, that part of the job is rescheduled. The TaskTracker on each node spawns off a separate Java Virtual Machine process to prevent the TaskTracker itself from failing if the running job crashes the JVM. A heartbeat is sent from the TaskTracker to the JobTracker every few minutes to check its status. The Job Tracker and TaskTracker status and information is exposed by Jetty and can be viewed from a web browser.
Some of the terminologies in the MapReduce process are:
MasterNode – Place where JobTracker runs and which accepts job requests from clients
SlaveNode – It is the place where the mapping and reducing programs are run
JobTracker – it is the entity that schedules the jobs and tracks the jobs assigned using Task Tracker
TaskTracker – It is the entity that actually tracks the tasks and provides the report status to the JobTracker
Job – A MapReduce job is the execution of the Mapper & Reducer program across a dataset
Task – the execution of the Mapper & Reducer program on a specific data section
TaskAttempt – A particular task execution attempt on a SlaveNode
Map Function – The map function takes an input and produces a set of intermediate key value pairs.
Reduce Function – The reduce function accepts an Intermediate key and a set of values for that key. It merges together these values to form a smaller set of values. The intermediate values are supplied to user’s reduce function via an iterator.
Thus map reduce converts each task to a group of map reduce functions and each map and reduce task can be performed by different machines. The results can be merged back to produce the required output.
D. How YARN works: Yet Another Resource Negotiator
MapReduce has undergone a complete overhaul in Hadoop 0.23 and we now have, what we call, MapReduce 2.0 (MRv2) or YARN.
Apache Hadoop YARN is a sub-project of Hadoop at the Apache Software Foundation introduced in Hadoop 2.0 that separates the resource management and processing components. YARN was born of a need to enable a broader array of interaction patterns for data stored in HDFS beyond MapReduce. The YARN-based architecture of Hadoop 2.0 provides a more general processing platform that is not constrained to MapReduce.
YARN enhances the power of a Hadoop compute cluster in the following ways:
- Scalability: The processing power in data centers continues to grow quickly. Because YARN ResourceManager focuses exclusively on scheduling, it can manage those larger clusters much more easily.
- Compatibility with MapReduce: Existing MapReduce applications and users can run on top of YARN without disruption to their existing processes.
- Improved cluster utilization: The ResourceManager is a pure scheduler that optimizes cluster utilization according to criteria such as capacity guarantees, fairness, and SLAs. Also, unlike before, there are no named map and reduce slots, which helps to better utilize cluster resources.
- Support for workloads other than MapReduce: Additional programming models such as graph processing and iterative modeling are now possible for data processing. These added models allow enterprises to realize near real-time processing and increased ROI on their Hadoop investments.
- Agility: With MapReduce becoming a user-land library, it can evolve independently of the underlying resource manager layer and in a much more agile manner.
The fundamental idea of YARN is to split up the two major responsibilities of the JobTracker/TaskTracker into separate entities:
- a global ResourceManager
- a per-application ApplicationMaster
- a per-node slave NodeManager
- a per-application container running on a NodeManager
The ResourceManager and the NodeManager form the new, and generic, system for managing applications in a distributed manner. The ResourceManager is the ultimate authority that arbitrates resources among all the applications in the system. The per-application ApplicationMaster is a framework-specific entity and is tasked with negotiating resources from the ResourceManager and working with the NodeManager(s) to execute and monitor the component tasks. The ResourceManager has a scheduler, which is responsible for allocating resources to the various running applications, according to constraints such as queue capacities, user-limits, etc. The scheduler performs its scheduling function based on the resource requirements of the applications. The NodeManager is the per-machine slave, which is responsible for launching the applications’ containers, monitoring their resource usage (CPU, memory, disk, network) and reporting the same to the ResourceManager. Each ApplicationMaster has the responsibility of negotiating appropriate resource containers from the scheduler, tracking their status, and monitoring their progress. From the system perspective, the ApplicationMaster runs as a normal container.
TEZ
Tez is an extensible framework for building high performance batch and interactive data processing applications, coordinated by YARN in Apache Hadoop. Tez improves the MapReduce paradigm by dramatically improving its speed while maintaining MapReduce’s ability to scale to petabytes of data. Important Hadoop ecosystem projects like Apache Hive and Apache Pig use Apache Tez, as do a growing number of third party data access applications developed for the broader Hadoop ecosystem.
Apache Tez provides a developer API and framework to write native YARN applications that bridge the spectrum of interactive and batch workloads. It allows those data access applications to work with petabytes of data over thousands of nodes. The Apache Tez component library allows developers to create Hadoop applications that integrate natively with Apache Hadoop YARN and perform well within mixed workload clusters.
Since Tez is extensible and embeddable, it provides the fit-to-purpose freedom to express highly optimized data processing applications, giving them an advantage over end-user-facing engines such as MapReduce and Apache Spark. Tez also offers a customizable execution architecture that allows users to express complex computations as dataflow graphs, permitting dynamic performance optimizations based on real information about the data and the resources required to process it.
MPP
MPP stands for Massive Parallel Processing, this is the approach in grid computing when all the separate nodes of your grid are participating in the coordinated computations. MPP DBMSs are the database management systems built on top of this approach. In these systems each query you are staring is split into a set of coordinated processes executed by the nodes of your MPP grid in parallel, splitting the computations the way they are running times faster than in traditional SMP RDBMS systems. One additional advantage that this architecture delivers to you is the scalability, because you can easily scale the grid by adding new nodes into it. To be able to handle huge amounts of data, the data in these solutions is usually split between nodes (sharded) the way that each node processes only its local data. This further speeds up the processing of the data, because using shared storage for this kind of design would be a huge overkill – more complex, more expensive, less scalable, higher network utilization, less parallelism. This is why most of the MPP DBMS solutions are shared-nothing and work on DAS storage or the set of storage shelves shared between small groups of servers.
When to use Hadoop?
Hadoop is used for: (This is not an exhaustive list!)
- Log processing – Facebook, Yahoo
- Data Warehouse – Facebook, AOL
- Video and Image Analysis – New York Times, Eyealike
Till now, we have seen how Hadoop has made Big Data handling possible. But there are some scenarios where Hadoop implementation is not recommended.
When not to use Hadoop?
Following are some of those scenarios : (This is not an exhaustive list!)
- Low Latency data access : Quick access to small parts of data.
- Multiple data modification : Hadoop is a better fit only if we are primarily concerned about reading data and not modifying data.
- Lots of small files : Hadoop is suitable for scenarios, where we have few but large files.
- After knowing the best suitable use-cases, let us move on and look at a case study where Hadoop has done wonders.
Hate Hadoop? Then You’re Doing It Wrong
3. History
In 2003, Doug Cutting launches project Nutch to handle billions of searches and indexing millions of web pages. Later in Oct 2003 – Google releases papers with GFS (Google File System). In Dec 2004, Google releases papers with MapReduce. In 2005, Nutch used GFS and MapReduce to perform operations.
Hadoop was created by Doug Cutting and Mike Cafarella in 2005. It was originally developed to support distribution for the Nutch search engine project. Doug, who was working at Yahoo! at the time and is now Chief Architect of Cloudera.
The name Hadoop came from his son’s toy elephant. Cutting’s son was 2 years old at the time and just beginning to talk. He called his beloved stuffed yellow elephant “Hadoop” (with the stress on the first syllable). Now 12, Doug’s son often exclaims, “Why don’t you say my name, and why don’t I get royalties? I deserve to be famous for this!”
There are some similar stories about the name.
Later in Jan 2008, Yahoo released Hadoop as an open source project to Apache Software Foundation. In July 2008, Apache tested a 4000 node cluster with Hadoop successfully. In 2009, Hadoop successfully sorted a petabyte of data in less than 17 hours to handle billions of searches and indexing millions of web pages. Moving ahead in Dec 2011, Apache Hadoop released version 1.0. Later in Aug 2013, Version 2.0.6 was available, in Sep 2016, Version 3.0.0-alpha was available and in Dec 2017, Version 3.0.0 was available.
Is Hadoop dying?
Nowadays a lot of people start to talk about Hadoop is dying and that Spark is the future. But what exactly this means?
Hadoop itself is not dying but MapReduce that is batch orientate is being replaced to Spark because Spark can run in memory and with this be faster. The other thing is about the rising of the clouds, and is now possible to use cloud storage to replace HDFS and is totally possible to use tools like Spark without Hadoop. In the other hand, Hadoop 3 is supporting integration with Object Storage System and already changes yarn to run with GPU.
Hadoop 3
With Hadoop 3.0 YARN will enable running all types of clusters and mix CPU and GPU intensive processes. For example, by integrating TensorFlow with YARN an end-user can seamlessly manage resources across multiple Deep Learning applications and other workloads, such as Spark, Hive or MapReduce.
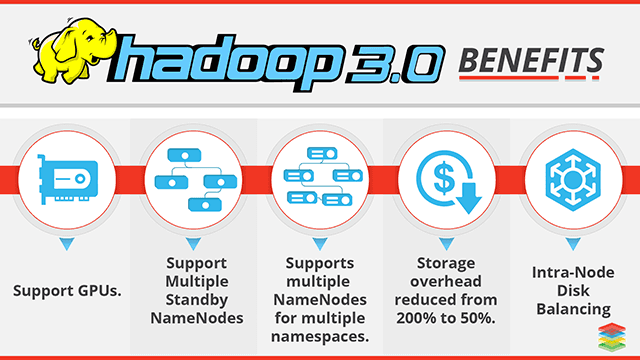
The major changes are:
- Minimum Required Java Version in Hadoop 3 is 8
- Support for Erasure Encoding in HDFS
- YARN Timeline Service v.2
- Shell Script Rewrite
- Shaded Client Jars
- Support for Opportunistic Containers
- MapReduce Task-Level Native Optimization
- Support for More than 2 NameNodes
- Default Ports of Multiple Services have been Changed
- Support for Filesystem Connector
- Intra-DataNode Balancer
- Reworked Daemon and Task Heap Management
4. Courses
https://hackernoon.com/top-5-hadoop-courses-for-big-data-professionals-best-of-lot-7998f593d138
https://dzone.com/articles/top-5-hadoop-courses-to-learn-online
https://www.datasciencecentral.com/profiles/blogs/hadoop-tutorials
5. Books
Hadoop: The Definitive Guide is the best option to start.
http://grut-computing.com/HadoopBook.pdf
https://github.com/tomwhite/hadoop-book
6. Influencers List
https://www.kdnuggets.com/2015/05/greycampus-150-most-influential-people-big-data-hadoop.html
7. Podcasts
https://player.fm/podcasts/Hadoop
8. Newsletters
https://blog.feedspot.com/hadoop_blogs/