
![]()
How heya?
if you’re not familiar with Big Data, I suggest you have a look on my post “What is Big Data?” before.
This post is a collection of links, videos, tutorials, blogs and books that I found mixed with my opinion.
Table of contents
1. What is Apache Spark?
2. Architecture
3. History
4. Courses
5. Books
6. Influencers List
7. Link
1. What is Apache Spark?
Apache Spark is an open source parallel processing framework for storing and processing Big Data across clustered computers. Spark can be used to perform computations much faster than what Hadoop can rather Hadoop and Spark can be used together efficiently. Spark is written in Scala, which is considered the primary language for interacting with the Spark Core engine, but it doesn’t require developers to know Scala, which executes inside a Java Virtual Machine (JVM). APIs for Java, Python, R, and Scala ensure Spark is within reach of a wide audience of developers, and they have embraced the software.
Apache Spark is most actively developed open source project in big data and probably the most widely used as well. Spark is a general purpose Execution Engine, which can perform its cluster management on top of Big Data very quickly and efficiently. It is rapidly increasing its features and capabilities like libraries to perform different types of Analytics.
Apache Spark is a fast, in-memory data processing engine with elegant and expressive development APIs to allow data workers to efficiently execute streaming, machine learning or SQL workloads that require fast iterative access to datasets. With Spark running on Apache Hadoop YARN, developers everywhere can now create applications to exploit Spark’s power, derive insights, and enrich their data science workloads within a single, shared dataset in Hadoop.
Apache Spark is a lightning-fast cluster computing technology, designed for fast computation. It is based on Hadoop MapReduce and it extends the MapReduce model to efficiently use it for more types of computations, which includes interactive queries and stream processing. The main feature of Spark is its in-memory cluster computing that increases the processing speed of an application
The Hadoop YARN-based architecture provides the foundation that enables Spark and other applications to share a common cluster and dataset while ensuring consistent levels of service and response. Spark is now one of many data access engines that work with YARN in HDP.
Spark is designed for data science and its abstraction makes data science easier.
Spark also includes MLlib, a library that provides a growing set of machine algorithms for common data science techniques: Classification, Regression, Collaborative Filtering, Clustering and Dimensionality Reduction.
The Driver and the Executer
Spark uses a master-slave architecture. A driver coordinates many distributed workers in order to execute tasks in a distributed manner while a resource manager deals with the resource allocation to get the tasks done.
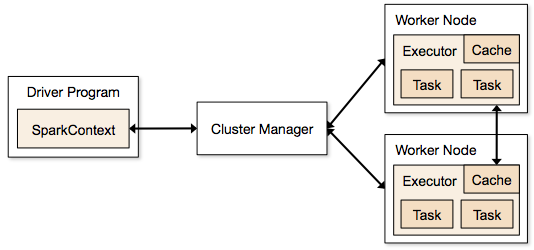
Driver
Think of it as the “Orchestrator”. The driver is where the main method runs. It converts the program into tasks and then schedules the tasks to the executors. The driver has at its disposal 3 different ways of communicating with the executors; Broadcast, Take and DAG. It controls the execution of a Spark application and maintains all of the states of the Spark cluster, which includes the state and tasks of the executors. The driver must interface with the cluster manager in order to get physical resources and launch executors. To put this in simple terms, this process is just a process on a physical machine that is responsible for maintaining the state of the application running on the cluster.
- Broadcast Action: The driver transmits the necessary data to each executor. This action is optimal for data sets under a million records, +- 1gb of data. This action can become a very expensive task.
- Take Action: Driver takes data from all Executors. This action can be a very expensive and dangerous action as the driver might run out of memory and the network could become overwhelmed.
- DAG Action: (Direct Acyclic Graph) This is the by far least expensive action out of the three. It transmits control flow logic from the driver to the executors.
Executer – “Workers”
Executers execute the delegated tasks from the driver within a JVM instance. Executors are launched at the beginning of a Spark application and normally run for the whole life span of an application. This method allows for data to persist in memory while different tasks are loaded in and out of the execute throughout the application’s lifespan.
The JVM worker environments in Hadoop MapReduce in stark contrast powers down and powers up for each task. The consequence of this is that Hadoop must perform reads and writes on disk at the start and end of every task.
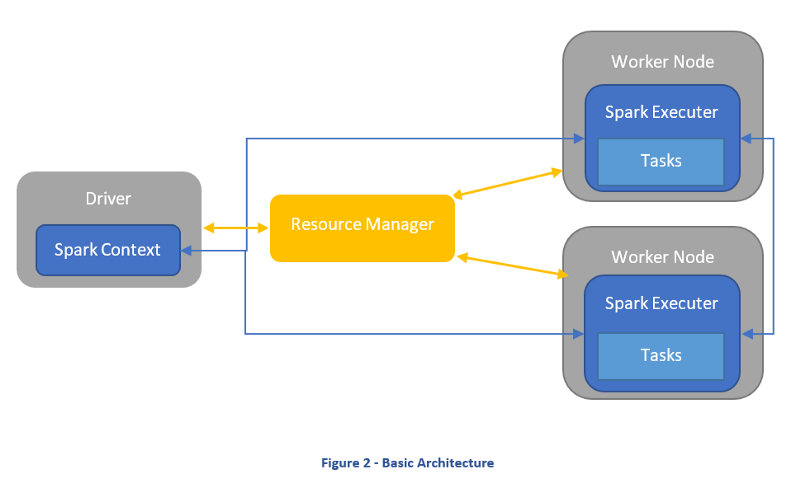
Cluster manager
This is responsible for allocating resources across the spark application. The Spark context is capable of connecting to several types of cluster managers like Mesos, Yarn or Kubernetes apart from the Spark’s standalone cluster manager.
Cluster Manager is responsible for maintaining a cluster of machines that will run your Spark Application. Cluster managers have their own ‘driver’ and ‘worker’ abstractions, but the difference is that these are tied to physical machines rather than processes.
Spark Context
It holds a connection with Spark cluster manager. All Spark applications run as independent set of processes, coordinated by a SparkContext in a program.
Spark has three data representations viz RDD, Dataframe, Dataset. For each data representation, Spark has a different API. Dataframe is much faster than RDD because it has metadata (some information about data) associated with it, which allows Spark to optimize query plan.
A nice place to understand more about RDD, Dataframe, Dataset is this article: “A Tale of Three Apache Spark APIs: RDDs vs DataFrames and Datasets” https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-dataframes-and-datasets.html
RDD
A Resilient Distributed Dataset (RDD), is the primary data abstraction in Apache Spark and the core of Spark. Represents an immutable, partitioned collection of elements that can be operated on in parallel. This class contains the basic operations available on all RDDs, such as map, filter, and persist. Is the most basic data abstraction in Spark. It is a fault-tolerant collection of elements that can be operated on in parallel.RDD is an immutable distributed collection of elements of your data, partitioned across nodes in your cluster that can be operated in parallel with a low-level API that offers transformations and actions.
We can apply 2 types of operations on RDDs
Transformation: Transformation refers to the operation applied on a RDD to create new RDD.
Action: Actions refer to an operation which also apply on RDD that perform computation and send the result back to driver.
Example: Map (Transformation) performs operation on each element of RDD and returns a new RDD. But, in case of Reduce (Action), it reduces / aggregates the output of a map by applying some functions (Reduce by key).
RDDs use Shared Variable
The parallel operations in Apache Spark use shared variable. It means that whenever a task is sent by a driver to executors program in a cluster, a copy of shared variable is sent to each node in a cluster, so that they can use this variable while performing task. Accumulator and Broadcast are the two types of shared variables supported by Apache Spark.
Broadcast: We can use the Broadcast variable to save the copy of data across all node.
Accumulator: In Accumulator variables are used for aggregating the information.
How to Create RDD in Apache Spark
Existing storage: When we want to create a RDD though existing storage in driver program (which we would like to be parallelized). For example, converting a list to RDD, which is already created in a driver program.
External sources: When we want to create a RDD though external sources such as a shared file system, HDFS, HBase, or any data source offering a Hadoop Input Format.
The features of RDDs :
- Resilient, i.e. fault-tolerant with the help of RDD lineage graph and so able to recompute missing or damaged partitions due to node failures.
- Distributed with data residing on multiple nodes in a cluster.
- Dataset is a collection of partitioned data with primitive values or values of values, e.g. tuples or other objects (that represent records of the data you work with).
The key reasons RDDs are an abstraction that works better for distributed data processing, is because they don’t feature some of the issues that MapReduce, the older paradigm for data processing (which Spark is replacing increasingly). Chiefly, these are:
1. Replication: Replication of data on different parts of a cluster, is a feature of HDFS that enables data to be stored in a fault-tolerant manner. Spark’s RDDs address fault tolerance by using a lineage graph. The different name (resilient, as opposed to replicated) indicates this difference of implementation in the core functionality of Spark
2. Serialization: Serialization in MapReduce bogs it down, speed wise, in operations like shuffling and sorting.
Dataframe
It is a distributed collection of data organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame but with lot more stuff under the hood. DataFrame allows developers to impose a structure onto a distributed collection of data, allowing higher-level abstractions. From 2.0, the Data frames API was merged with Dataset. Now a DataFrame is a Dataset organized into named columns.
Data frames can be created from RDDs.
Dataframes also tries to solve a lot of performance issues that spark had with non-jvm languages like python and R . Historically, using RDD’s in python was much slower than in Scala. With Dataframes, code written all the languages perform the same with some exceptions.
Dataset
It is a collection of strongly-typed domain-specific objects that can be transformed in parallel using functional or relational operations. A logical plan is created and updated for each transformation and a final logical plan is converted to a physical plan when an action is invoked. Spark’s catalyst
optimizer optimizes the logical plan and generates a physical plan for efficient execution in a parallel and distributed manner. Further, there are Encoders generates optimized, lower memory footprint binary structure. Encoders know the schema of the records. This is how they offer significantly faster
serialization and deserialization (comparing to the default Java or Kryo serializers).
The main advantage of Datasets is Type safety. When using Datasets we are assured that both the syntax errors and Analysis errors are caught during compile time. In contrast with Dataframes, where a syntax error can be caught during compile time but an Analysis error such as referring to a nonexisting column name would be caught only once you run it. The run times can be quite expensive and also as a developer it would be nice to have compiler and IDE’s to do these jobs for you.
2. Architecture
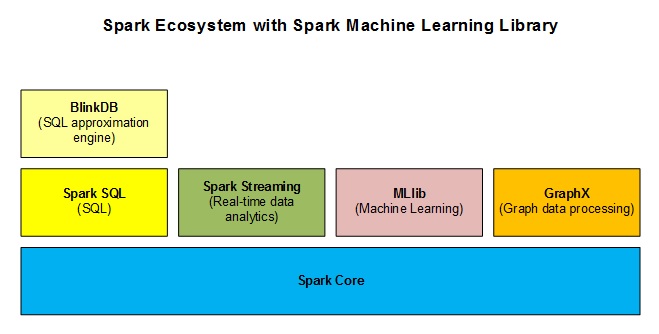
Spark Core
Spark Core is the base engine for large-scale parallel and distributed data processing. Further, additional libraries which are built on the top of the core allows diverse workloads for streaming, SQL, and machine learning. It is responsible for memory management and fault recovery, scheduling, distributing and monitoring jobs on a cluster & interacting with storage systems.
BlindDB
BlindDB or Blind Database is also known as an Approximate SQL database. If there is a huge amount of data barraging and you are not really interested in accuracy, or in exact results, but just want to have a rough or an approximate picture, BlindDB gets you the same. Firing a query, doing some sort of sampling, and giving out some output is called Approximate SQL. Isn’t it a new and interesting concept? Many a time, when you do not require accurate results, sampling would certainly do.
Spark SQL
Spark SQL is a new module in Spark which integrates relational processing with Spark’s functional programming API. It supports querying data either via SQL or via the Hive Query Language. For those of you familiar with RDBMS, Spark SQL will be an easy transition from your earlier tools where you can extend the boundaries of traditional relational data processing.
Spark Streaming
Spark Streaming is one of those unique features, which have empowered Spark to potentially take the role of Apache Storm. Spark Streaming mainly enables you to create analytical and interactive applications for live streaming data. You can do the streaming of the data and then, Spark can run its operations from the streamed data itself.
Structured Streaming
Structured Streaming (added in Spark 2.x) is to Spark Streaming what Spark SQL was to the Spark Core APIs: A higher-level API and easier abstraction for writing applications. In the case of Structure Streaming, the higher-level API essentially allows developers to create infinite streaming dataframes and datasets. It also solves some very real pain points that users have struggled with in the earlier framework, especially concerning dealing with event-time aggregations and late delivery of messages. All queries on structured streams go through the Catalyst query optimizer, and can even be run in an interactive manner, allowing users to perform SQL queries against live streaming data.
Structured Streaming is still a rather new part of Apache Spark, having been marked as production-ready in the Spark 2.2 release. However, Structured Streaming is the future of streaming applications with the platform, so if you’re building a new streaming application, you should use Structured Streaming. The legacy Spark Streaming APIs will continue to be supported, but the project recommends porting over to Structured Streaming, as the new method makes writing and maintaining streaming code a lot more bearable.
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
MLLib
MLLib is a machine learning library like Mahout. It is built on top of Spark, and has the provision to support many machine learning algorithms. But the point difference with Mahout is that it runs almost 100 times faster than MapReduce. It is not yet as enriched as Mahout, but it is coming up pretty well, even though it is still in the initial stage of growth.
GraphX
For graphs and graphical computations, Spark has its own Graph Computation Engine, called GraphX. It is similar to other widely used graph processing tools or databases, like Neo4j, Girafe, and many other distributed graph databases.
3. History
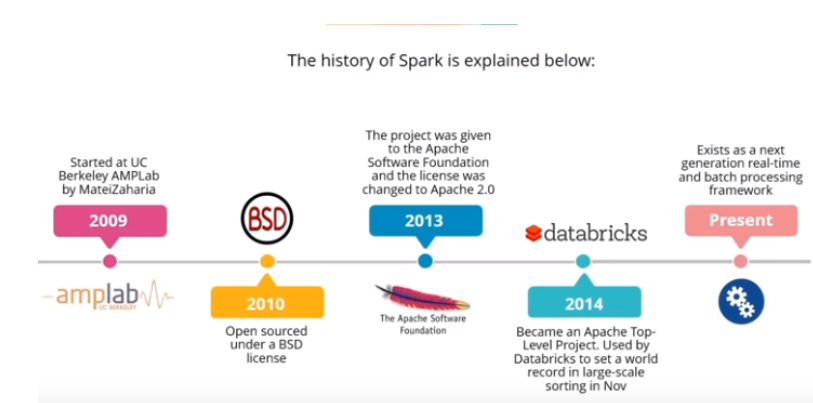
Apache Spark is about to turn 10 years old.
Spark started in 2009 as a research project in the UC Berkeley RAD Lab, later to become the AMPLab. The researchers in the lab had previously been working on Hadoop MapReduce, and observed that MapReduce was inefficient for iterative and interactive computing jobs. Thus, from the beginning, Spark was designed to be fast for interactive queries and iterative algorithms, bringing in ideas like support for in-memory storage and efficient fault recovery.
Soon after its creation it was already 10–20× faster than MapReduce for certain jobs.
Some of Spark’s first users were other groups inside UC Berkeley, including machine learning researchers such as the Mobile Millennium project, which used Spark to monitor and predict traffic congestion in the San Francisco Bay Area.
Spark was first open sourced in March 2010, and was transferred to the Apache Software Foundation in June 2013, where it is now a top-level project. It is an open source project that has been built and is maintained by a thriving and diverse community of developers. In addition to UC Berkeley, major contributors to Spark include Databricks, Yahoo!, and Intel.
Internet powerhouses such as Netflix, Yahoo, and eBay have deployed Spark at massive scale, collectively processing multiple petabytes of data on clusters of over 8,000 nodes. It has quickly become the largest open source community in big data, with over 1000 contributors from 250+ organizations.
In-memory computation
The biggest advantage of Apache Spark comes from the fact that it saves and loads the data in and from the RAM rather than from the disk (Hard Drive). If we talk about memory hierarchy, RAM has much higher processing speed than Hard Drive (illustrated in figure below). Since the prices of memory has come down significantly in last few years, in-memory computations have gained a lot of momentum.
Spark uses in-memory computations to speed up 100 times faster than Hadoop framew
Spark VS Hadoop
Speed
- Apache Spark — it’s a lightning-fast cluster computing tool. Spark runs applications up to 100x faster in memory and 10x faster on disk than Hadoop by reducing the number of read-write cycles to disk and storing intermediate data in-memory.
- Hadoop MapReduce — MapReduce reads and writes from disk, which slows down the processing speed and overall efficiency.
Ease of Use
- Apache Spark — Spark’s many libraries facilitate the execution of lots of major high-level operators with RDD (Resilient Distributed Dataset).
- Hadoop — In MapReduce, developers need to hand-code every operation, which can make it more difficult to use for complex projects at scale.
Handling Large Sets of Data
- Apache Spark — since Spark is optimized for speed and computational efficiency by storing most of the data in memory and not on disk, it can underperform Hadoop MapReduce when the size of the data becomes so large that insufficient RAM becomes an issue.
- Hadoop — Hadoop MapReduce allows parallel processing of huge amounts of data. It breaks a large chunk into smaller ones to be processed separately on different data nodes. In case the resulting dataset is larger than available RAM, Hadoop MapReduce may outperform Spark. It’s a good solution if the speed of processing is not critical and tasks can be left running overnight to generate results in the morning.
Hadoop vs Spark
How do Hadoop and Spark Stack Up?
4. Courses
https://mapr.com/company/press-releases/free-apache-spark-courses-and-discounted-certification-exam/
5. Books
Spark: The Definitive Guide is the best option to start.
oreilly – pdf – Github
Learning Spark: Lightning-Fast Big Data Analysis
oreilly – pdf – Github
Advanced Analytics with Spark: Patterns for Learning from Data at Scale
oreilly
High Performance Spark: Best Practices for Scaling and Optimizing Apache Spark
oreilly
6. Influencers List
@SparkAISummit
@BigData_LDN
@caroljmcdonald
@marklit82
@holdenkarau
@schmarzo
7. Link
Practical apache spark 10 minutes