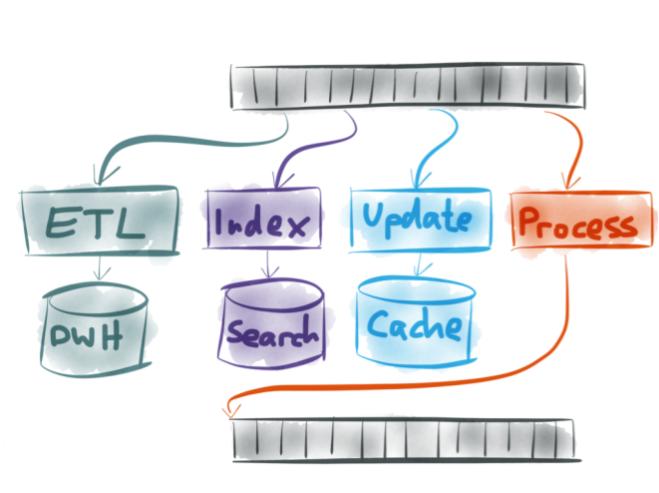
What is Apache Flink?

How goes the battle? This post is a collection of links, videos, tutorials, blogs, and books that I found mixed with my opinion. What is Apache Flink? From the Official website, Apache Flink is a framework and distributed processing engine… Continue Reading