

How’s it going there?
if you’re not familiar with Big Data, I suggest you have a look on my post “What is Big Data?
” before.
This post is a collection of links, videos, tutorials, blogs and books that I found mixed with my opinion.
Table of contents
1. What is Data Lake?
2. History
3. courses
4. Books
5. Influencers List
6. Link
1.What is Data Lake?
Like Big Data is something no stratforward to explain and there’s no unique answer to that. Even though there is no single definition for Data Lake that is universally accepted, there are some common concepts and I’ll try to cover in this post.
I like the simple definition:
Data lake is a place to store your structured and unstructured data, as well as a method for organizing large volumes of highly diverse data from diverse sources.
I Googled about and I found a different answer.
A data lake is a massive, easily accessible, centralized repository of large volumes of structured and unstructured data. The data lake architecture is a store-everything approach to big data. Data are not classified when they are stored in the repository, as the value of the data is not clear at the outset. As a result, data preparation is eliminated. A data lake is thus less structured compared to a conventional data warehouse. When the data are accessed, only then are they classified, organized or analyzed.
Other answer.
A data lake is a collection of storage instances of various data assets additional to the originating data sources. These assets are stored in a near-exact, or even exact, copy of the source format. The purpose of a data lake is to present an unrefined view of data to only the most highly skilled analysts, to help them explore their data refinement and analysis techniques independent of any of the system-of-record compromises that may exist in a traditional analytic data store (such as a data mart or data warehouse).
According to Nick Huedecker at Gartner,
Data lakes are marketed as enterprise-wide data management platforms for analyzing disparate sources of data in its native format. The idea is simple: instead of placing data in a purpose-built data store, you move it into a data lake in its original format. This eliminates the upfront costs of data ingestion, like transformation. Once data is placed into the lake, it’s available for analysis by everyone in the organization.
Forbes try to explain Data Lake making a comparison with Data Warehouse:
https://www.forbes.com/sites/bernardmarr/2018/08/27/what-is-a-data-lake-a-super-simple-explanation-for-anyone/#3905f53776e0
Martin Fowler.
The idea is to have a single store for all of the raw data that anyone in an organisation might need to analyse. Commonly people use Hadoop to work on the data in the lake, but the concept is broader than just Hadoop.
https://martinfowler.com/bliki/DataLake.html
Data Lakes by Oracle
https://blogs.oracle.com/bigdata/data-lakes
Data lakes are becoming increasingly important as people, especially in business and technology, want to perform broad data exploration and discovery. Bringing data together into a single place or most of it in a single place can be useful for that.
Most data lake implementations are probably based on the Hadoop ecosystem, which is a set of tools that makes it easy to use MapReduce or other computation models.
All data lakes have some distributed file systems. Data should be persisted in raw format because it’s not possible to structure them on ingestion. To achieve this, ingested data should be left in raw form; later they can be structured with transformation processes. As you can see, there is a need for a dedicated layer which allows unstructured data to persist efficiently. In Hadoop, HDFS fulfills this role.
To build ingestion and transformation processes, we need to use some computation system that is fault-tolerant, easily scalable, and efficient at processing large data sets. Nowadays, streaming systems are gaining in popularity. Spark, Storm, Flink… At the beginning of BigData, only MapReduce was available, which was (and still is) used as a bulk-processing framework.
Scalability in a computation system requires resource management. In a data lake, we have huge amounts of data requiring thousands of nodes. Prioritization is achieved by allocating resources and queuing tasks. Some transformations require more resources; some require less. Major tasks get more resources. This resources allocation role in Hadoop is performed by YARN.

What is Streaming?
Streaming is data that is continuously generated by different sources. Such data should be processed incrementally using Stream Processing techniques without having access to all of the data. In addition, it should be considered that concept drift may happen in the data which means that the properties of the stream may change over time.
It is usually used in the context of big data in which it is generated by many different sources at high speed.
Data streaming can also be explained as a technology used to deliver content to devices over the internet, and it allows users to access the content immediately, rather than having to wait for it to be downloaded. Big data is forcing many organizations to focus on storage costs, which brings interest to data lakes and data streams.
In Big Data management, data streaming is the continuous high-speed transfer of large amounts of data from a source system to a target. By efficiently processing and analyzing real-time data streams to glean business insight, data streaming can provide up-to-the-second analytics that enable businesses to quickly react to changing conditions
What can Data Lake do?
This is not an exhaustive list!
- Ingestion of semi-structured and unstructured data sources (aka big data) such as equipment readings, telemetry data, logs, streaming data, and so forth. A data lake is a great solution for storing IoT (Internet of Things) type of data which has traditionally been more difficult to store, and can support near real-time analysis. Optionally, you can also add structured data (i.e., extracted from a relational data source) to a data lake if your objective is a single repository of all data to be available via the lake.
- Experimental analysis of data before its value or purpose has been fully defined. Agility is important for every business these days, so a data lake can play an important role in “proof of value” type of situations because of the “ELT” approach discussed above.
- Advanced analytics support. A data lake is useful for data scientists and analysts to provision and experiment with data.
- Archival and historical data storage. Sometimes data is used infrequently, but does need to be available for analysis. A data lake strategy can be very valuable to support an active archive strategy.
- Support for Lambda architecture which includes a speed layer, batch layer, and serving layer.
- Preparation for data warehousing. Using a data lake as a staging area of a data warehouse is one way to utilize the lake, particularly if you are getting started.
- Augment a data warehouse. A data lake may contain data that isn’t easily stored in a data warehouse, or isn’t queried frequently. The data lake might be accessed via federated queries which make its separation from the DW transparent to end users via a data virtualization layer.
- Distributed processing capabilities associated with a logical data warehouse.
- Storage of all organizational data to support downstream reporting & analysis activities. Some organizations wish to achieve a single storage repository for all types of data. Frequently, the goal is to store as much data as possible to support any type of analysis that might yield valuable findings.
- Application support. In addition to analysis by people, a data lake can be a data source for a front-end application. The data lake might also act as a publisher for a downstream application (though ingestion of data into the data lake for purposes of analytics remains the most frequently cited use).

Under the umbrella of Data Lake there are many of technologies and concepts. This is not an exhaustive list!
Data ingestion
Data ingestion is the process of flowing data from its origin to one or more data stores, such as a data lake, though this can also include databases and search engines.
Sources can be clickstreams, data center logs, sensors, APIs or even databases. They use various data formats (structured, unstructured, semi-structured, multi-structured), can make data available in a stream or batches, and support various protocols for data movement.
There are two processing frameworks which “ingest” data into data lakes:
- Batch processing – Millions of blocks of data processed over long periods of time (hours-to-days).
- Stream processing – Small batches of data processed in real-time. Stream processing is becoming increasingly valuable for businesses that harness real-time analytics.

Data Marts
A Data Mart is an archive of stored, normally structured data, typically used and controlled by a specific community or department. It is normally smaller and more focused than a Data Warehouse and, currently, is often a subdivision of Data Warehouses. Data Marts were the first evolutionary step in the physical reality of Data Warehouses and Data Lakes
Data Silos
Data Silos are part of a Data Warehouse and similar to Data Marts, but much more isolated. Data Silos are insulated management systems that cannot work with other systems. A Data Silo contains fixed data that is controlled by one department and is cut off from other parts of the organization. They tend to form within large organizations due to the different goals and priorities of individual departments. Data Silos also form when departments compete with one another instead of working as a team toward common business goals.
Data Warehouses
Data Warehouses are centralized repositories of information that can be researched for purposes of making better informed decisions. The data comes from a wide range of sources and is often unstructured. Data is accessed through the use of business intelligence tools, SQL clients, and other Analytics applications.
Data swamp
In data lakes there are many things going on and it’s not possible to manage them manually. Without constraints and a thoughtful approach to processes, a data lake will become degenerated very quickly. If ingested data do not contain business information, then we can’t find the right context for them. If everyone generates anonymous data without lineage, then we will have tons of useless data. No one will know what is going on. Who is the author of changes? Where did the data come from? Everything starts to look like a data swamp.
Data Mining
Data mining is defined as “knowledge discovery in databases,” and is how data scientists uncover previously unseen patterns and truths through various models. data mining is about sifting through large sets of data to uncover patterns, trends, and other truths that may not have been previously visible.
Data Cleansing
The goal of data cleansing is to improve data quality and utility by catching and correcting errors before it is transferred to a target database or data warehouse. Manual data cleansing may or may not be realistic, depending on the amount of data and number of data sources your company has. Regardless of the methodology, data cleansing presents a handful of challenges, such as correcting mismatches, ensuring that columns are in the same order, and checking that data (such as date or currency) is in the same format.
Data Quality
People try to describe data quality using terms like complete, accurate, accessible, and de-duped. And while each of these words describes a specific element of data quality, the larger concept of data quality is really about whether or not that data fulfills the purpose or purposes you want to use it for.
ETL
ETL stands for “Extract, Transform, Load”, and is the common paradigm by which data from multiple systems is combined to a single database, data store, or warehouse for legacy storage or analytics.
ELT
ELT is a process that involves extracting the data, loading it to the target warehouse, and then transforming it after it is loaded. In this case, the work of transforming the data is completed by the target database.
Data extraction
Data extraction is a process that involves retrieval of data from various sources. Frequently, companies extract data in order to process it further, migrate the data to a data repository (such as a data warehouse or a data lake) or to further analyze it. It’s common to transform the data as a part of this process.
Data loading
Data loading refers to the “load” component of ETL. After data is retrieved and combined from multiple sources (extracted), cleaned and formatted (transformed), it is then loaded into a storage system, such as a cloud data warehouse.
Data Transformation
Data transformation is the process of converting data from one format or structure into another format or structure. Data transformation is critical to activities such as data integration and data management. Data transformation can include a range of activities: you might convert data types, cleanse data by removing nulls or duplicate data, enrich the data, or perform aggregations, depending on the needs of your project.
Data Migration
Data migration is simply the process of moving data from a source system to a target system. Companies have many different reasons for migrating data. You may want to migrate data when you acquire another company and you need to integrate that company’s data. Or, you may want to integrate data from different departments within your company so the data is available across your entire business. You may want to move your data from an on-premise platform to a cloud platform. Or, perhaps you’re moving from an outdated data storage system to a new database or data storage system. The concept of data migration is simple, but it can sometimes be a complex process.
Lambda architecture
Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch and stream-processing methods. This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The two view outputs may be joined before presentation. The rise of lambda architecture is correlated with the growth of big data, real-time analytics, and the drive to mitigate the latencies of map-reduce.
Kappa Architecture
Kappa Architecture is a software architecture pattern. Rather than using a relational DB like SQL or a key-value store like Cassandra, the canonical data store in a Kappa Architecture system is an append-only immutable log. From the log, data is streamed through a computational system and fed into auxiliary stores for serving.
Kappa Architecture is a simplification of Lambda Architecture. A Kappa Architecture system is like a Lambda Architecture system with the batch processing system removed. To replace batch processing, data is simply fed through the streaming system quickly.
SIEM Security information and event management
The underlying principles of every SIEM system is to aggregate relevant data from multiple sources, identify deviations from the norm and take appropriate action. For example, when a potential issue is detected, a SIEM might log additional information, generate an alert and instruct other security controls to stop an activity’s progress.
Security information and event management (SIEM) is an approach to security management that combines SIM (security information management) and SEM (security event management) functions into one security management system. The acronym SIEM is pronounced “sim” with a silent e.
software collects and aggregates log data generated throughout the organization’s technology infrastructure, from host systems and applications to network and security devices such as firewalls and antivirus filters.The software then identifies and categorizes incidents and events, as well as analyzes them.
SNA social network analysis
Social network analysis is the process of investigating social structures through the use of networks and graph theory. It characterizes networked structures in terms of nodes (individual actors, people, or things within the network) and the ties, edges, or links (relationships or interactions) that connect them.
Data lake vs data warehouse
Data warehouses rely on structure and clean data, whereas data lakes allow data to be in its most natural form. This is because advanced analytic tools and mining software intake raw data and transform it into useful insight.
Both data lakes and data warehouses are repositories for data. That’s about the only similarity between the two. Now, let’s touch on some of the key differences:
- Data lakes are designed to support all types of data, whereas data warehouses make use of highly structured data – in most cases.
- Data lakes store all data that may or may not be analyzed at some point in the future. This principle doesn’t apply to data warehouses since irrelevant data is typically eliminated due to limited storage.
- The scale between data lakes and data warehouses is drastically different due to our previous points. Supporting all types of data and storing that data (even if it’s not immediately useful) means data lakes need to be highly scalable.
- Thanks to metadata (data about data), users working with a data lake can gain basic insight about the data quickly. In data warehouses, it often requires a member of the development team to access the data – which could create a bottleneck.
- Lastly, the intense data management required for data warehouses means they’re typically more expensive to maintain compared to data lakes.
I’m believer that modern data warehousing is still very important. Therefore, a data lake itself, doesn’t entirely replace the need for a data warehouse (or data marts) which contain cleansed data in a user-friendly format. The data warehouse doesn’t absolutely have to be in a relational database anymore, but it does need a semantic layer which is easy to work with that most business users can access for the most common reporting needs.
There’s always tradeoffs between performing analytics on a data lake versus from a cleansed data warehouse: Query performance, data load performance, scalability, reusability, data quality, and so forth. Therefore, I believe that a data lake and a data warehouse are complementary technologies that can offer balance. For a fast analysis by a highly qualified analyst or data scientist, especially exploratory analysis, the data lake is appealing. For delivering cleansed, user-friendly data to a large number of users across the organization, the data warehouse still rules.
2. History
Data Lakes allow Data Scientists to mine and analyze large amounts of Big Data. Big Data, which was used for years without an official name, was labeled by Roger Magoulas in 2005. He was describing a large amount of data that seemed impossible to manage or research using the traditional SQL tools available at the time. Hadoop (2008) provided the search engine needed for locating and processing unstructured data on a massive scale, opening the door for Big Data research.
In October of 2010, James Dixon, founder and former CTO of Pentaho, came up with the term “Data Lake”
Data Lake came from the idea that the data drop in one place, and this place becomes a lake.
Visiting a large lake is always a very pleasant feeling. The water in the lake is in its purest form and there are different activities different people perform on the Lake. Some are people are fishing, some people are enjoying a boat ride, this lake also supplies drinking water to people. In short, the same lake is used for multiple purposes. Data Lake Architecture, like the water in the lake, data in a data lake is in the purest possible form. Like the lake, it caters to need to different people, those who want to fish or those who want to take a boat ride or those who want to get drinking water from it, a data lake architecture caters to multiple personas.
This is not a official history about how the name came from. If you know please leave one comment.
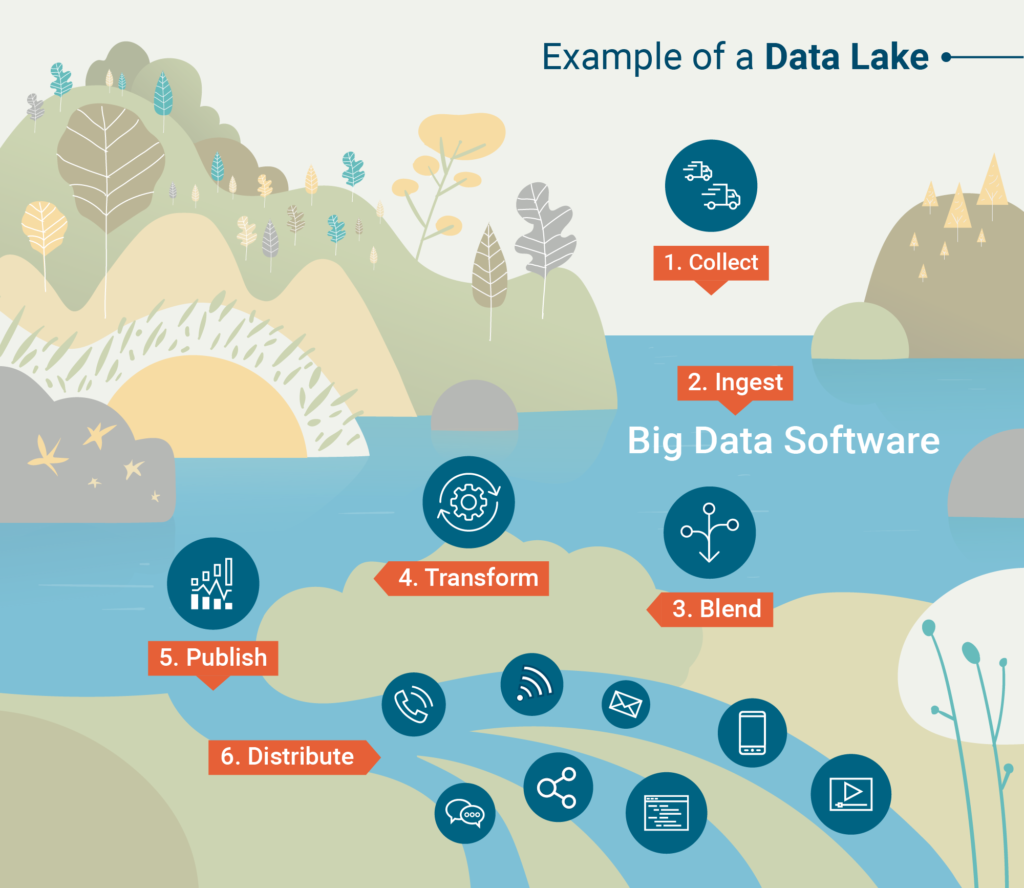
3. Courses
https://www.whizlabs.com/blog/top-big-data-influencers/
https://www.mooc-list.com/course/data-lakes-big-data-edcast
4. Books
The Enterprise Big Data Lake
oreilly
Data Lake for Enterprises
oreilly
5. Influencers List
https://www.whizlabs.com/blog/top-big-data-influencers/
6. Link
Data lakes and the promise of unsiloed data
Every software engineer should know about real time datas
Questioning the lambda architecture
What’s the Difference Between a Data Lake, Data Warehouse and Database?