

Alright boss?
The complexity of Hadoop ecosystem comes from having many tools that can be used, and not from using Hadoop itself.
The objective of this Apache Hadoop ecosystem components tutorial is to have an overview of what are the different components of Hadoop ecosystem that make Hadoop so powerful, to give you a nice overview of some Hadoop related products and about somel Hadoop distributions in the market. I did some research and this is what I know or found and probably is not a exhaustive list!
if you’re not familiar with Big Data or Data lake, I suggest you have a look on my previous post “What is Big Data?” and “What is data lake?” before.
This post is a collection of links, videos, tutorials, blogs and books that I found mixed with my opinion.
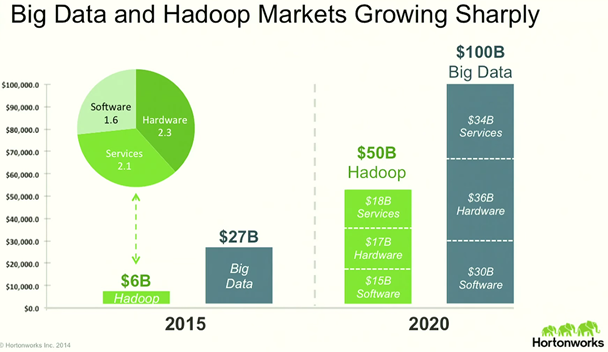
Hadoop Ecosystem
What does Hadoop Ecosystem mean?
Hadoop Ecosystem is neither a programming language nor a service, it is a platform or framework which solves big data problems. You can consider it as a suite which encompasses a number of services (ingesting, storing, analyzing and maintaining) inside it. The Hadoop ecosystem includes both official Apache open source projects and a wide range of commercial tools and solutions. Most of the solutions available in the Hadoop ecosystem are intended to supplement one or two of Hadoop’s four core elements (HDFS, MapReduce, YARN, and Common). However, the commercially available framework solutions provide more comprehensive functionality.

The Hadoop Ecosystem Table https://hadoopecosystemtable.github.io/
Hortonworks https://hortonworks.com/ecosystems/
Hive
Hive is data warehousing software that addresses how data is structured and queried in distributed Hadoop clusters. Hive is also a popular development environment that is used to write queries for data in the Hadoop environment. It provides tools for ETL operations and brings some SQL-like capabilities to the environment. Hive is a declarative language that is used to develop applications for the Hadoop environment, however it does not support real-time queries.
Pig
Pig is a procedural language for developing parallel processing applications for large data sets in the Hadoop environment. Pig is an alternative to Java programming for MapReduce, and automatically generates MapReduce functions. Pig includes Pig Latin, which is a scripting language. Pig translates Pig Latin scripts into MapReduce, which can then run on YARN and process data in the HDFS cluster. Pig is popular because it automates some of the complexity in MapReduce development.
HBase
HBase is a scalable, distributed, NoSQL database that sits atop the HFDS. It was designed to store structured data in tables that could have billions of rows and millions of columns. It has been deployed to power historical searches through large data sets, especially when the desired data is contained within a large amount of unimportant or irrelevant data (also known as sparse data sets). It is also an underlying technology behind several large messaging applications, including Facebook’s.
Oozie
Oozie is the workflow scheduler that was developed as part of the Apache Hadoop project. It manages how workflows start and execute, and also controls the execution path. Oozie is a server-based Java web application that uses workflow definitions written in hPDL, which is an XML Process Definition Language similar to JBOSS JBPM jPDL. Oozie only supports specific workflow types, so other workload schedulers are commonly used instead of or in addition to Oozie in Hadoop environments.
Sqoop
Think of Sqoop as a front-end loader for big data. Sqoop is a command-line interface that facilitates moving bulk data from Hadoop into relational databases and other structured data stores. Using Sqoop replaces the need to develop scripts to export and import data. One common use case is to move data from an enterprise data warehouse to a Hadoop cluster for ETL processing. Performing ETL on the commodity Hadoop cluster is resource efficient, while Sqoop provides a practical transfer method.
HCatalog
It is a table and storage management layer for Hadoop. HCatalog supports different components available in Hadoop ecosystems like MapReduce, Hive, and Pig to easily read and write data from the cluster. HCatalog is a key component of Hive that enables the user to store their data in any format and structure.
By default, HCatalog supports RCFile, CSV, JSON, sequenceFile and ORC file formats.
Avro
Acro is a part of Hadoop ecosystem and is a most popular Data serialization system. Avro is an open source project that provides data serialization and data exchange services for Hadoop. These services can be used together or independently. Big data can exchange programs written in different languages using Avro.
Thrift
It is a software framework for scalable cross-language services development. Thrift is an interface definition language for RPC(Remote procedure call) communication. Hadoop does a lot of RPC calls so there is a possibility of using Hadoop Ecosystem componet Apache Thrift for performance or other reasons.
Drill
The main purpose of the Hadoop Ecosystem Component is large-scale data processing including structured and semi-structured data. It is a low latency distributed query engine that is designed to scale to several thousands of nodes and query petabytes of data. The drill is the first distributed SQL query engine that has a schema-free model.
Mahout
Mahout is open source framework for creating scalable machine learning algorithm and data mining library. Once data is stored in Hadoop HDFS, mahout provides the data science tools to automatically find meaningful patterns in those big data sets.
Flume
Flume efficiently collects, aggregate and moves a large amount of data from its origin and sending it back to HDFS. It is fault tolerant and reliable mechanism. This Hadoop Ecosystem component allows the data flow from the source into Hadoop environment. It uses a simple extensible data model that allows for the online analytic application. Using Flume, we can get the data from multiple servers immediately into hadoop.
Ambari
Ambari, another Hadop ecosystem component, is a management platform for provisioning, managing, monitoring and securing apache Hadoop cluster. Hadoop management gets simpler as Ambari provide consistent, secure platform for operational control.
Zookeeper
Apache Zookeeper is a centralized service and a Hadoop Ecosystem component for maintaining configuration information, naming, providing distributed synchronization, and providing group services. Zookeeper manages and coordinates a large cluster of machines.
Lucene
Apache Lucene is a full-text search engine which can be used from various programming languages, is a free and open-source information retrieval software library, originally written completely in Java by Doug Cutting. It is supported by the Apache Software Foundation and is released under the Apache Software License.
Sorl
Solr is an open-source enterprise-search platform, written in Java, from the Apache Lucene project. Its major features include full-text search, hit highlighting, faceted search, real-time indexing, dynamic clustering, database integration, NoSQL features and rich document handling.
Phoenix
Apache Phoenix is an open source, massively parallel, relational database engine supporting OLTP for Hadoop using Apache HBase as its backing store.
Presto
Presto is a high performance, distributed SQL query engine for big data. Its architecture allows users to query a variety of data sources such as Hadoop, AWS S3, Alluxio, MySQL, Cassandra, Kafka, and MongoDB. One can even query data from multiple data sources within a single query.
Zeppelin
Apache Zeppelin is a multi-purposed web-based notebook which brings data ingestion, data exploration, visualization, sharing and collaboration features to Hadoop and Spark.
Storm
Apache Storm is a distributed stream processing computation framework written predominantly in the Clojure programming language. Originally created by Nathan Marz and team at BackType, the project was open sourced after being acquired by Twitter.
Flink
Apache Flink is an open-source stream-processing framework developed by the Apache Software Foundation. The core of Apache Flink is a distributed streaming data-flow engine written in Java and Scala. Flink executes arbitrary dataflow programs in a data-parallel and pipelined manner.
Samza
Apache Samza is an open-source near-realtime, asynchronous computational framework for stream processing developed by the Apache Software Foundation in Scala and Java.
Arrow
Apache Arrow is a cross-language development platform for in-memory data. It specifies a standardized language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware.
Airflow
Airflow is a platform to programmatically author, schedule and monitor workflows. Use airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The airflow scheduler executes your tasks on an array of workers while following the specified dependencies.
Blazingdb
BlazingSQL is a distributed GPU-accelerated SQL engine with data lake integration, where data lakes are huge quantities of raw data that are stored in a flat architecture. It is ACID-compliant. BlazingSQL targets ETL workloads and aims to perform efficient read IO and OLAP querying. BlazingDB refers to the company and BlazingSQL refers to the product.
Chukwa
A data collection system for managing large distributed systems.
Impala
The open source, native analytic database for Apache Hadoop. Impala is shipped by Cloudera, MapR, Oracle, and Amazon.
Get started with Hadoop: From evaluation to your first production cluster
https://www.oreilly.com/ideas/getting-started-with-hadoop
Hadoop distributions

When talk about HAdoop distribution the top 3 most famous are Cloudera, Hortonworks and MapR.
September 2018 Cloudera and Hortonworks announcing a merge to be completed summer 2019.
Cloudera and Hortonworks Announce Merger to Create World’s Leading Next Generation Data Platform and Deliver Industry’s First Enterprise Data Cloud https://www.cloudera.com/about/news-and-blogs/press-releases/2018-10-03-cloudera-and-hortonworks-announce-merger-to-create-worlds-leading-next-generation-data-platform-and-deliver-industrys-first-enterprise-data-cloud.html
Cloudera and Hortonworks Complete Planned Merger https://www.cloudera.com/about/news-and-blogs/press-releases/2019-01-03-cloudera-and-hortonworks-complete-planned-merger.html
- Cloudera offers the highest performance and lowest cost platform for using data to drive better business outcomes. Cloudera has a track record of bringing new open source solutions into its platform (such as Apache Spark, Apache HBase, and Apache Parquet) that are eventually adopted by the community at large. Cloudera Navigator provides everything your organization needs to keep sensitive data safe and secure while still meeting compliance requirements. Cloudera Manager is the easiest way to administer Hadoop in any environment, with advanced features like intelligent configuration defaults, customized monitoring, and robust troubleshooting. Cloudera delivers the modern data management and analytics…
- Hortonworks Sandbox is a personal, portable Apache Hadoop environment that comes with dozens of interactive Hadoop and it’s ecosystem tutorials and the most exciting developments from the latest HDP distribution. Hortonworks Sandbox provides performance gains up to 10 times for applications that store large datasets such as state management, through a revamped Spark Streaming state tracking API. It provides seamless Data Access to achieve higher performance with Spark. Also provides dynamic Executor Allocation to utilize cluster resources efficiently through Dynamic Executor Allocation functionality that automatically expands and shrinks resources based on utilization. Hortonworks Sandbox
- MapR Converged Data Platform integrates the power of Hadoop and Spark with global event streaming, real-time database capabilities, and enterprise storage for developing and running innovative data applications. Modules include MapR-FS, MapR-DB, and MapR Streams. Its enterprise- friendly design provides a familiar set of file and data management services, including a global namespace, high availability, data protection, self-healing clusters, access control, real-time performance, secure multi-tenancy, and management and monitoring. MapR tests and integrates open source ecosystem projects such as Hive, Pig, Apache HBase and Mahout, among others. MapR Community
Commercial Hadoop Vendors
1) Amazon Elastic MapReduce
2) Microsoft Azure’s HDInsight – Cloud based Hadoop Distribution
3) IBM Open Platform
4) Pivotal Big Data Suite
5) Datameer Professional
6) Datastax Enterprise Analytics
7) Dell – Cloudera Apache Hadoop Solution.
8) Oracle
Top Hadoop Appliances
Hadoop Appliances providers offer hardware optimised for Apache Hadoop or enterprise versions .
Dell provides PowerEdge servers, Cloudera Enterprise Basic Edition and Dell Professional Services, Dell PowerEdge servers with Intel Xeon processors, Dell Networking and Cloudera Enterprise and Dell In-Memory Appliance for Cloudera Enterprise with Apache Spark.
EMC provides Greenplum HD and Greenplum MR. EMC provides Pivotal HD, which is an Apache Hadoop distribution that natively integrates EMC Greenplum massively parallel processing (MPP) database technology with the Apache Hadoop framework.
Teradata Appliance for Hadoop provides optimized hardware, flexible configurations, high-speed connectors, enhanced software usability features, proactive systems monitoring, intuitive management portals, continuous availability, and linear scalability.
HP AppSystem for Apache Hadoop is an enterprise ready Apache Hadoop platform and provides RHEL v6.1, Cloudera Enterprise Core – the market leading Apache Hadoop software, HP Insight CMU v7.0 and a sandbox that includes HP Vertica Community Edition v6.1
NetApp Open Solution for Hadoop provides a ready to deploy, enterprise class infrastructure for the Hadoop platform to control and gain insights from big data.
Oracle Big Data Appliance X6-2 Starter Rack contains six Oracle Sun x86 servers within a full-sized rack with redundant Infiniband switches and power distribution units. Includes all Cloudera Enterprise Technology software including Cloudera CDH, Cloudera Manager, and Cloudera RTQ (Impala).
Top Hadoop Managed Services
Amazon EMR
Amazon EMR simplifies big data processing, providing a managed Hadoop framework that makes it easy, fast, and cost effective way to distribute and process vast amounts data across dynamically scalable Amazon EC2 instances.
Microsoft HDInisght
HDInsight is a managed Apache Hadoop, Spark, R, HBase, and Storm cloud service made easy. It provides a Data Lake service, Scale to petabytes on demand, Crunch all data structured, semi structured, unstructured and Develop in Java, .NET, and more. Provides Apache Hadoop, Spark, and R clusters in the cloud.
Google Cloud Platform
Google offers Apache Spark and Apache Hadoop clusters easily on Google Cloud Platform.
Qubole
Qubole Data Service (QDS) offers Hadoop as a Service and is a cloud computing solution that makes medium and large-scale data processing accessible, easy, fast and in
IBM BigInsights
IBM BigInsights on Cloud provides Hadoop-as-a-service on IBM’s SoftLayer global cloud infrastructure. It offers the performance and security of an on-premises deployment.
Teradata Cloud for Hadoop
Teradata Cloud for Hadoop includes Teradata developed software components that make Hadoop ready for the enterprise: high availability, performance, scalability, monitoring, manageability, data transformation, data security, and a full range of tools and utilities.
Altiscale Data Cloud
Altiscale Data Cloud is a fully managed Big Data platform, delivering instant access to production ready Apache Hadoop and Apache Spark on the world’s best Big Data infrastructure.
Rackspace Apache
Rackspace Apache Hadoop distribution includes common tools like MapReduce, HDFS, Pig, Hive, YARN, and Tez. Rackspace provide root access to the application itself, allowing users to interact directly with the core platform.
Oracle
Oracle offers a Cloudera solution on the top of the Oracle cloud infrastructure.
Links
https://data-flair.training/blogs/hadoop-ecosystem-components/