
![]()
How goes the battle?
This post is a collection of links, videos, tutorials, blogs, and books that I found mixed with my opinion.
What is Apache Flink?
From the Official website, Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and any scale.
From Wikipedia, Flink is an open-source platform that is a streaming data flow engine that provides communication, fault-tolerance, and data distribution for distributed computations over data streams.
From the internet, Flink is a distributed processing engine and a scalable data analytics framework. You can use Flink to process data streams at a large scale and to deliver real-time analytical insights about your processed data with your streaming application.
The key vision for Apache Flink is to overcome and reduce the complexity that has been faced by other distributed data-driven engines. This is achieved by integrating query optimization, concepts from database systems, and efficient parallel in-memory and out-of-core algorithms, with the MapReduce framework. So, Flink is mainly based on the streaming model, it iterates data by using streaming architecture. Flink pipelined architecture allows processing the streaming data faster with lower latency than micro-batch architectures.
Since its very early days, Apache Flink has followed the philosophy of taking a unified approach to batch and streaming. The core building block is the “continuous processing of unbounded data streams, with batch as a special, bounded set of those streams.”
It can support streaming and batch processing applications based on the same Flink runtime.
Of course, The “streaming first, with batch as a special case of streaming” philosophy is supported by various projects and has often been cited as a powerful way to build data applications that unify batch and stream data processing and help greatly reduce the complexity of data infrastructures.
Batch and Streaming: Two sides of the same coin
Picture 1: cover both traditional batch workloads and streaming workloads with one
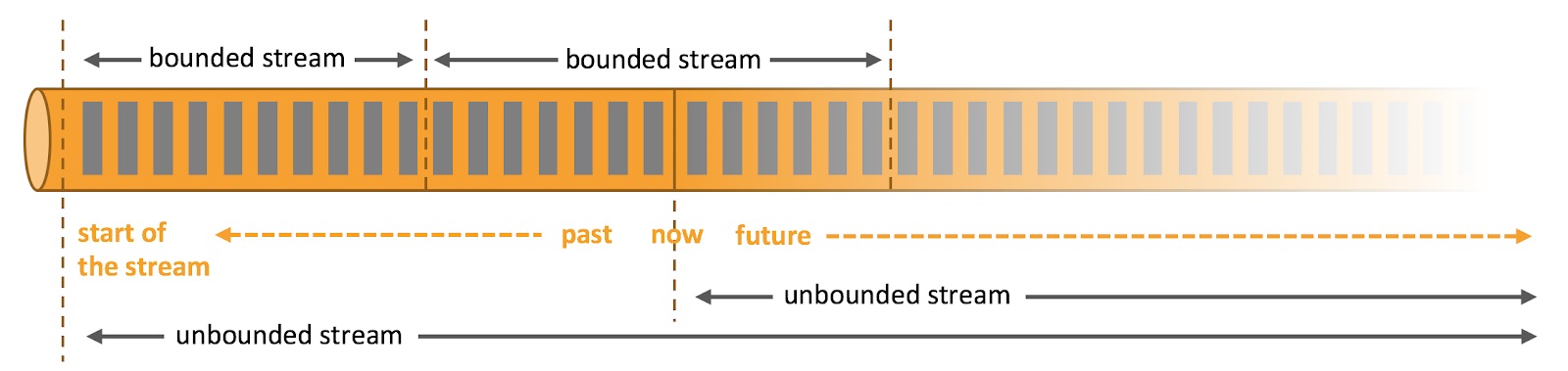
Data can be processed as unbounded or bounded streams.
- Unbounded streams have a start but no defined end. They do not terminate and provide data as it is generated. Unbounded streams must be continuously processed, i.e., events must be promptly handled after they have been ingested. It is not possible to wait for all input data to arrive because the input is unbounded and will not be complete at any point in time. Processing unbounded data often requires that events are ingested in a specific order, such as the order in which events occurred, to be able to reason about result completeness.
- Bounded streams have a defined start and end. Bounded streams can be processed by ingesting all data before performing any computations. Ordered ingestion is not required to process bounded streams because a bounded data set can always be sorted. Processing of bounded streams is also known as batch processing.
https://flink.apache.org/flink-architecture.html
History
Apache Flink was started under the project called The Stratosphere. In 2008 Volker Markl formed the idea for Stratosphere and attracted other co-principal Investigators from HU Berlin, TU Berlin, and the Hasso Plattner Institute Potsdam. They jointly worked on a vision and had already put great efforts into open-source deployment and systems building.
Later on, several decisive steps had been made so that the project could be popular in commercial, research, and open source communities. A commercial entity named this project as Stratosphere. After applying for Apache incubation in April 2014 Flink name was finalized.
Apache Flink Community, a subset of the Apache Software Foundation. Flink, which is now at version 1.11.0, is operated by a team of roughly 25 committers and is maintained by more than 340 contributors around the world.
The name Flink derives from the German word flink which means fast or agile (hence the logo, which is a red squirrel — a common sight in Berlin, where Apache Flink was partially created). Flink sprung from Stratosphere, a research project conducted by several European universities between 2010 and 2014.
What Can Apache Flink Do?
- Facilitate simultaneous streaming and batch processing.
- Process millions of records per minute.
- Power applications at scale.
- Utilize in-memory performance.
A large variety of enterprises choose Flink as a stream processing platform due to its ability to handle scale, stateful stream processing, and event time.
You can see a good explanation and several Fink scenarios here.
Packages Building blocks
The DataStream API is used as the core API to develop Flink streaming applications using Java or Scala programming languages. The core building blocks of a streaming application are datastream and transformation. In a Flink program, the incoming data streams from a source are transformed by a defined operation which results in one or more output streams to the sink as shown in the following illustration.
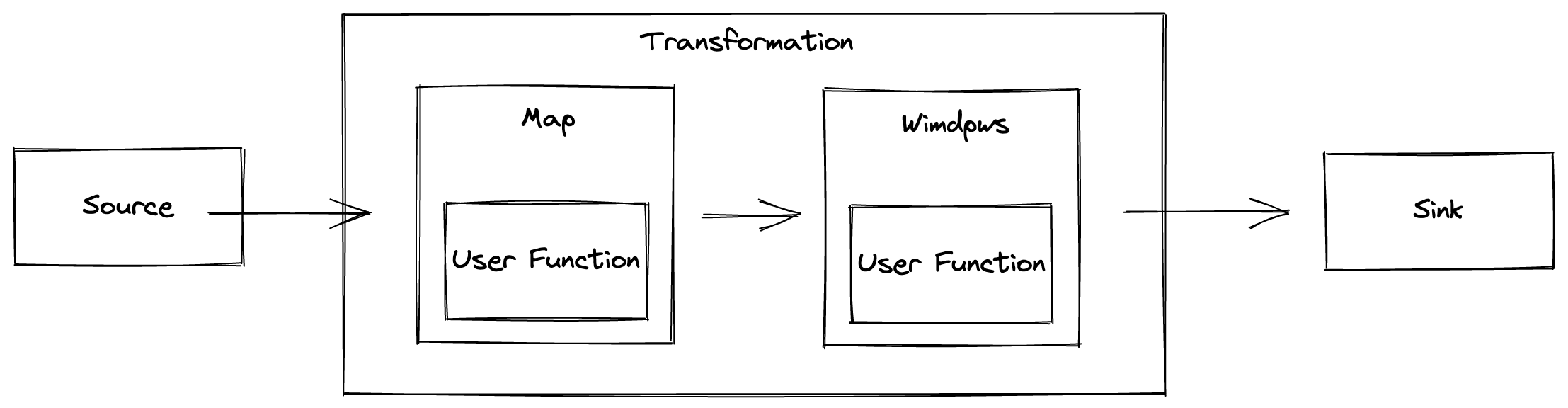
Picture 2: DataStream transformation
The basic object is DataStream
The DataStream object contains many useful methods to transform, split, and filter its data. Familiarity with the methods map, reduce, and filter is a good start; these are the main transformation methods:
- Map: receives T object and returns a result of an object of type R; the MapFunction is applied exactly once on each element of the DataStream object.
- Reduce: receives two consecutive values and returns one object after combining them into the same object type; this method runs on all values in the group until only a single value remains.
- Filter: receives T object and returns a stream of T objects; this method runs on each element in the DataStream but returns only those which the function returns true.
On a dataflow, one or more operations can be defined which can be processed in parallel and independently to each other. With windowing functions, different computations can be applied to different streams in the defined time window to further maintain the processing of events.
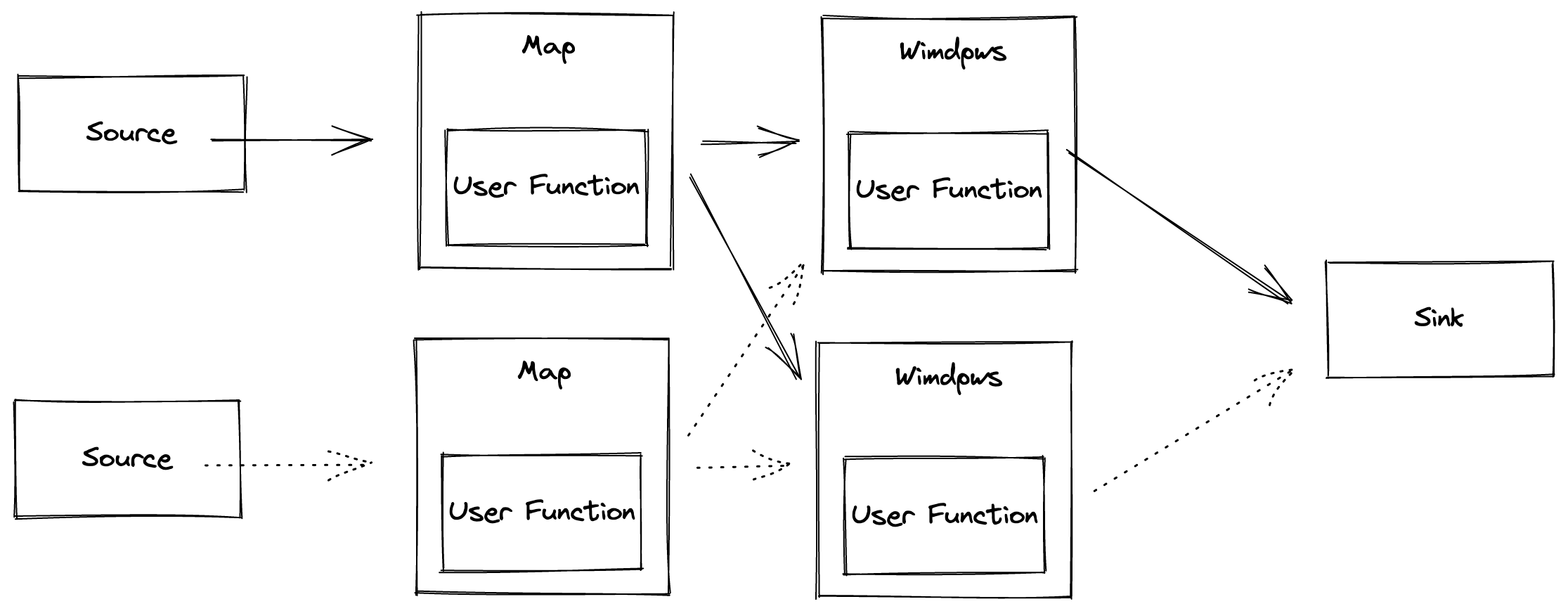
Picture 3: different computations can be applied to different streams
By definition, a stream is endless; therefore, the mechanism for processing is by defining frames in a time-based window. With that, the stream is divided into buckets for aggregation and analysis. The window definition is an operation on a DataStream object or one of its inheritors.
Although batch can be handled as a special case of stream processing, analyzing never-ending streaming data often requires a shift in the mindset and comes with its own terminology.
You can check my blog for windows explanation here on item 8.
Apache Flink window operator documentation.
There are several time-based windows:
- Tumbling window: Creates non-overlapping adjacent windows in a stream. It can either group elements by time or by count. Tumbling is the default configuration.
- Sliding window: Similar to the tumbling window, but here, windows can overlap.
- Session window: In this case, Flink groups events that occurred close in time to each other.
- Global window: In this case, Flink puts all elements in a single window. This is only useful if we define a custom trigger that defines when a window is finished.
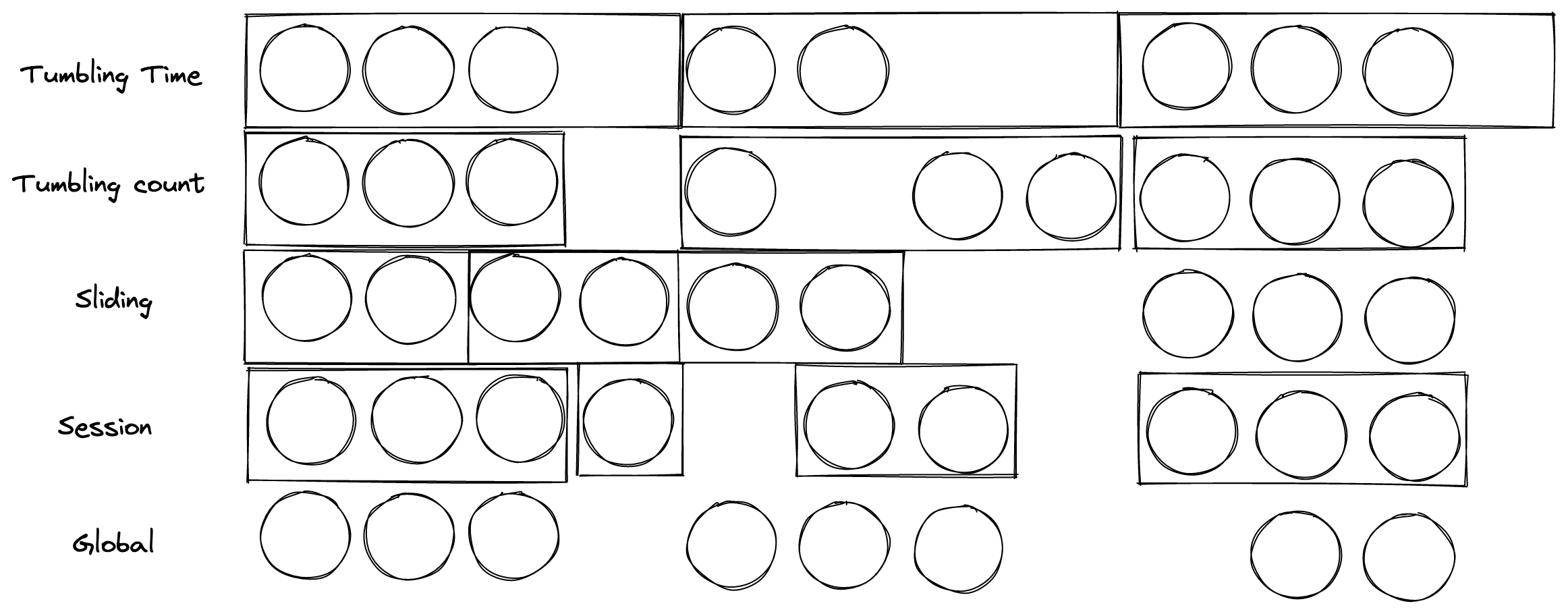
Picture 4: several time-based windows
Note: here is another place that could be explained using a Led Strip. Check out my blog post about Led Strip here.

Picture 5: my way to explain time-based windows
Besides transforming the data, Flink’s main purpose is to steer streams, after processing them into different destinations. These destinations are called “sinks”.
The notion of time is paramount for processing data streams. There are three options to define a timestamp:
- Processing time
- Event time
- Ingestion time
And you can check a nice explanation in the documentation here.
Books
Stream Processing with Apache Flink: Fundamentals, Implementation, and Operation of Streaming Applications by Fabian Hueske and Vasiliki Kalavri
Introduction to Apache Flink: Stream Processing for Real-time and Beyond by Ellen Friedman & Kostas Tzoumas
Courses
https://www.udemy.com/course/apache-flink-a-real-time-hands-on-course-on-flink/
https://www.udemy.com/course/learn-by-example-apache-flink/
Influencers List
@StephanEwen
@caito_200_OK
Links
You can find more information about Apache Flink and stream processes on the official website.
https://flink.apache.org/
https://data-flair.training/blogs/apache-flink-tutorial/
https://developpaper.com/apache-flink-infrastructure-and-concepts/
https://www.flink-forward.org/
https://tech.ebayinc.com/engineering/an-introduction-to-apache-flink/
Stay tuned! Is just a question of time for me to create a post to show how to install Apache Flink in a Raspberry PI and how to consume Kafka data from Flink.