
How goes the battle?
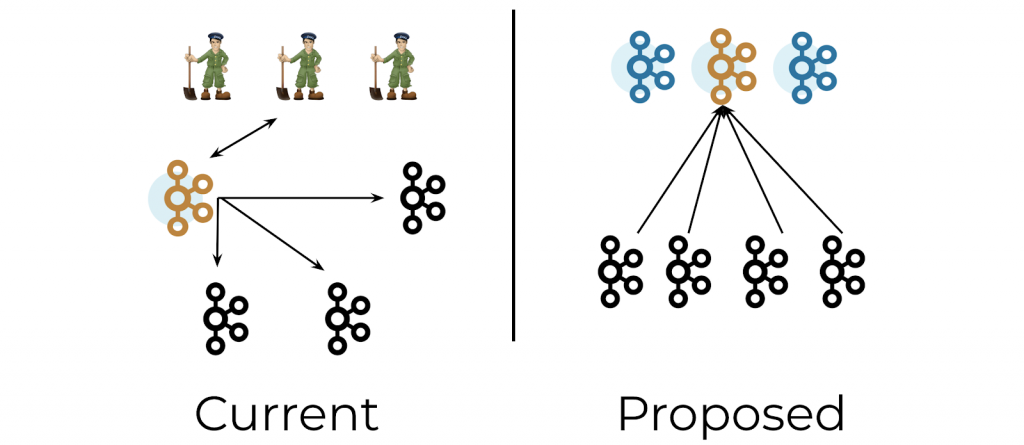
It is now possible to run Apache Kafka without Apache ZooKeeper! KRaft (aka KIP-500) mode Early Access Release is available to download.
This is another blog about Kafka and Raspberry PI, where I want to show how I did a simple KRaft test.
If you’re not familiar with Kafka, I suggest you have a look at my previous post What is Kafka and I suggest you check my blog about how I created a Raspberry PI Kafka cluster.
First, let’s download the new beta Kafka version.
1 | wget https://github.com/apache/kafka/archive/refs/tags/2.8.0-rc0.zip |
You can follow the GitHub readme. The first step is to generate an ID for your new cluster, using the kafka-storage tool
1 | ./bin/kafka-storage.sh random-uuid |
Format your storage directories.
1 | ./bin/kafka-storage.sh format -t -c ./config/kraft/server.properties |
Start the Kafka server on each node.
1 | ./bin/kafka-server-start.sh ./config/kraft/server.properties |
Create a topic.
1 | ./bin/kafka-topics.sh --create --topic igor --partitions 1 --replication-factor 1 --bootstrap-server localhost:9092 |
Producer
1 | kafka-console-producer.sh --broker-list localhost:9092 --topic igor |
Consumer
1 | kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic igor --from-beginning |
Depending on each Raspberry Pi version you are using you will need to change the bin/kafka-server-start.sh with
1 | export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M" |
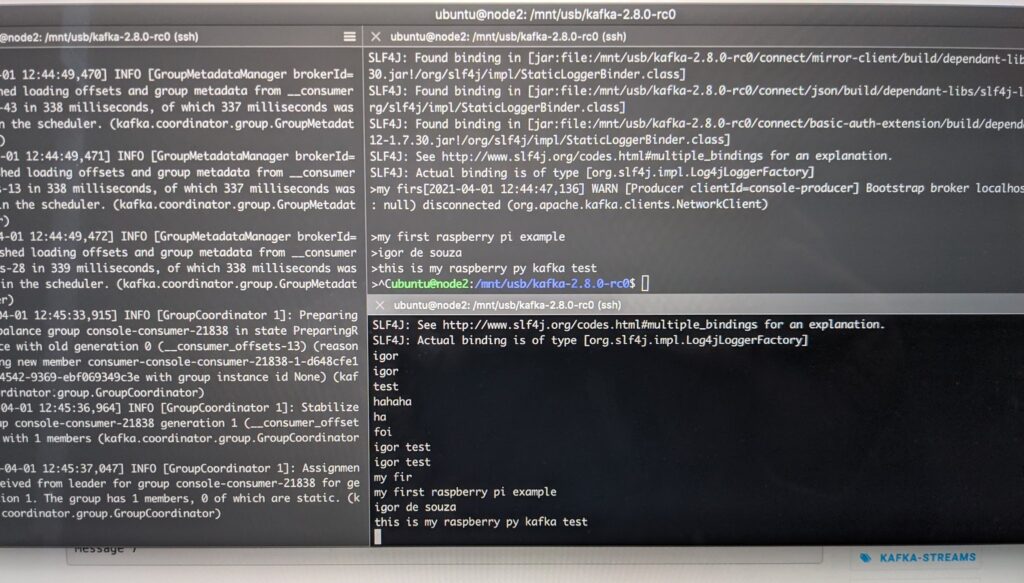
Picture 1: Terminal Logs
And that is it. Now you are ready to play with Kafka without Apache ZooKeeper on your Raspberry PI.
I came up with the idea to use a simple REST interface application to produce and consume Kafka data.
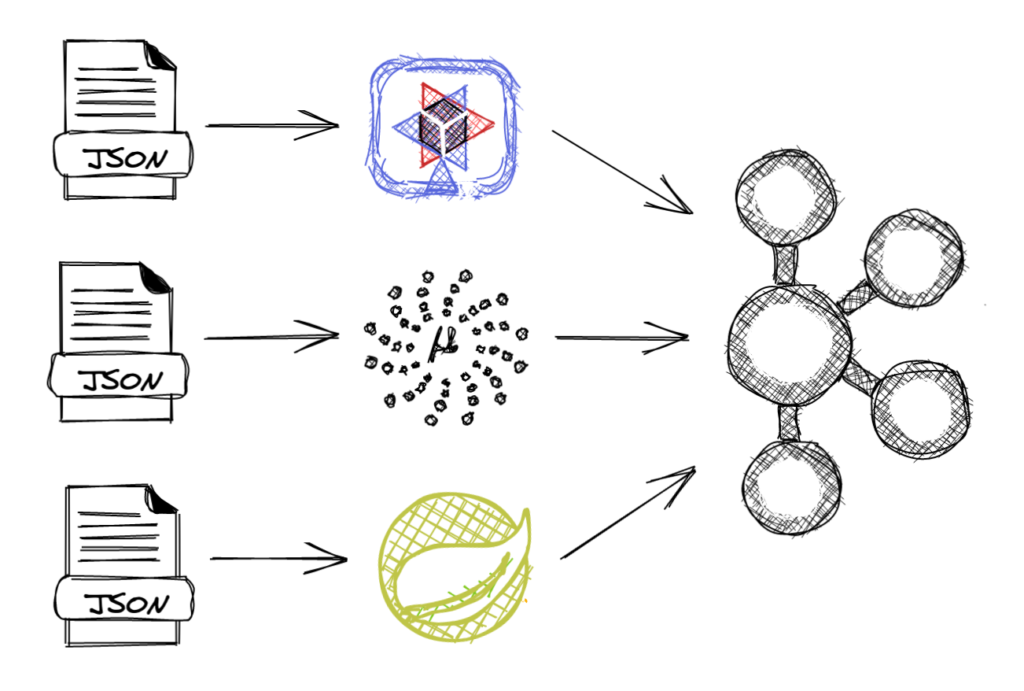
Picture 2: Kafka REST application. Created with excalidraw.com
It can be any webapp, it can use Quarkus, Micronaur, Spring or any other framework and I can run in a simple Raspberry PI zero. With that, I can integrate everything in my house with the Raspberry PI Kafka cluster.
KRaft is in Early Access and is not a production-ready product, but is perfect to test with Raspberry PI at home. No Zookeeper means less memory, less disk space and fewer steps to configure your cluster.